Loading... # 排序 ## 相关概念 数据按照一定规律顺次排列==》便于查找(数据存放在数据表中,按照关键字排序) 内部排序:待排序记录都在内存中 外部排序:待排序记录一部分在内存中,一部分在外存(更复杂) 排序算法衡量 * 时间效率:排序速度(比较次数和移动次数) * 空间效率:占内存辅助空间的大小 * 稳定性:A和B的关键字相等,排序后A、B的先后次序保持不变,则称这种排序算法是**稳定**的。 以顺序表存储 排序算法分类 * 规则 * 插入排序 * 交换排序 * 选择排序 * 归并排序 * 时间复杂度 * 简单排序O(n$^{2}$) * 先进排序O(nlog$_{2}$n) ## 插入排序 基本思想: 每步将一个待排序的对象,按其关键码大小,插入到前面已经排好序的一组对象的适当位置上,直到对象全部插入为止 即边插入边排序,保证子序列随时都是排好序的 ### 直接插入排序 整个排序过程为n-1趟插入,即先将序列中第1个记录看成是一个有序子序列,然后从第2个记录开始,逐个进行插入,直至整个序列有序 在一组数据中,若有25*,表示是后一个25 #### 步骤 * 在R[1,...,i-1]查找R[i]的插入位置,R[1,...,j].key<R[i].key<R[j+1,...,i-1].key * R[j+1,...,i-1]中的记录均后移一个位置 * 将R[i]插入到R[j+1]的位置上 #### 代码实现 ~~~C void InsertSort(SqList &L){ int i,j; for(i=2;i<=L.length;++i) if( L.r[i].key<L.r[i-1].key) //将L.r[i]插入有序子表 { L.r[0]=L.r[i]; // 复制为哨兵 L.r[i]=L.r[i-1]; for(j=i-2; L.r[0].key<L.r[j].key;--j) L.r[j+1]=L.r[j]; // 记录后移 L.r[j+1]=L.r[0]; //插入到正确位置 } } ~~~ #### 算法分析 最好时比较n-1次,移动0次 最坏时第i趟比较i次,移动i+1次 **性能:时间复杂度O(n$^{2}$) 空间复杂度O(1) 稳定** ### 折半插入排序 步骤和折半查找相似 减少关键字间的比较次数 #### 代码实现 ~~~C void BInsertSort ( SqList &L ) { for ( i = 2; i <= L.length ; ++i ) { L.r[0] = L.r[i]; low = 1; high = i-1; while ( low <= high ) { m = ( low + high ) / 2; if ( L.r[0].key < L.r[m]. key ) high = m -1; else low = m + 1; } for ( j=i-1; j>=high+1; - - j ) L.r[j+1] = L.r[j]; L.r[high+1] = L.r[0]; } } // BInsertSort ~~~ #### 算法分析 插入第i个对象时,需要经过[log$_{2}$ i ] + 1次关键字比较 和直接插入法相比,当n较大时,总比较次数要比直接插入好得多,当初始排列已接近有序时,直接插入执行次数较少,两者都依赖于对象的初始排列 减少了比较次数,但没减少移动次数,平均性能优于直接法 **性能:时间复杂度O(n$^{2}$) 空间复杂度O(1) 稳定** ### 希尔排序 #### 思想 直接插入在基本有序时,效率高;在待排序的记录个数较少时,效率较高 故先将待排记录序列分割成若干子序列,分别进行直接插入排序,带整个序列中的记录基本有序时,在对全体记录进行一次直接插入排序 #### 步骤 * dk 值较大,子序列中对象较少,速度较快; * dk 值逐渐变小,子序列中对象变多,但大多数对象已基本有序,所以排序速度仍然很快 #### 代码实现 dk值在dlta[]中 ~~~C void ShellSort(SqList &L,int dlta[ ],int t){ //按增量序列dlta[0…t-1]对顺序表L作Shell排序 for(k=0;k<t;++k) ShellInsert(L,dlta[k]); //增量为dlta[k]的一趟插入排序 } // ShellSort ~~~ ~~~C void ShellInsert(SqList &L,int dk) { //对顺序表L进行一趟增量为dk的Shell排序,dk为步长因子 for(i=dk+1;i<=L.length; ++ i) if(r[i].key < r[i-dk].key) { r[0]=r[i]; //暂存在r[0] for(j=i-dk; j>0 &&(r[0].key<r[j].key); j=j-dk) r[j+dk]=r[j]; //关键字较大的记录在子表中后移 r[j+dk]=r[0]; //在本趟结束时将r[i]插入到正确位置 } } ~~~ #### 算法分析 **时间复杂度:O(n$^{1.3}$) 空间复杂度O(1) 不稳定** 最后一个增质量必须为1 ## 交换排序 两两比较,发生逆序则交换,直到所有记录排好 ### 起泡排序 #### 思想 每趟不断将记录两两比较,前小后大 #### 代码实现 ~~~C void main() { int a[11]; /*a[0]不用,之用a[1]~a[10]*/ int i,j,t; printf("\nInput 10 numbers: \n"); for(i=1;i<=10;i++) scanf("%d",&a[i]); printf("\n"); for(j=1;j<=9;j++) for(i=1;i<=10-j;i++) if(a[i]>a[i+1]) { t=a[i]; a[i]=a[i+1]; a[i+1]=t; }//交换 for(i=1;i<=10;i++) printf("%d ",a[i]); } ~~~ ~~~c void bubble_sort(SqList &L) { int m,i,j,flag=1; RedType x; m=n-1; while((m>0)&&(flag==1)) { flag=0; for(j=1;j<=m;j++) if(L.r[j].key>L.r[j+1].key) { flag=1; x=L.r[j]; L.r[j]=L.r[j+1]; L.r[j+1]=x; //交换 }//endif m--; }//endwhile } ~~~ #### 算法分析 优点:每趟结束,最大值到最后位置,一旦下趟没交换,可提前结束排序 比较次数和移动次数与初始排列相关 最好的只需一趟排序,比较n-1次,不移动 最坏的需n-1趟排序,第i次比较n - i次,移动3(n - i) **时间复杂度O(n$^{2}$) 空间复杂度O(1) 稳定** ### 快速排序 #### 思想 * 任取一个元素(privotkey)为中心,所有小于它的前放,大于它的后放 * 对个子表重新选择中心元素并依次规则调整直到每个子表的元素只剩一个(可采用递归) ~~~C void main ( ) { QSort ( L, 1, L.length ); } void QSort ( SqList &L,int low, int high ) { if ( low < high ) { pivotloc = Partition(L, low, high ) ; Qsort (L, low, pivotloc-1) ; Qsort (L, pivotloc+1, high ) } } int Partition (SqList &L,int low,int high) { L.r[0] = L.r[low]; pivotkey = L.r[low].key; while ( low < high ) { while (low < high && L.r[high].key >= pivotkey ) --high; L.r[low] = L.r[high]; while ( low < high && L.r[low].key <= pivotkey ) ++low; L.r[high] = L.r[low]; } L.r[low]=L.r[0]; return low; } ~~~ #### 算法分析 时间复杂度O(nlog$_{2}$ n) 空间复杂度O(log$_{2}$ n)【递归需要栈空间】 不稳定(可选任意元素为支点) ## 选择排序 ### 简单选择排序 #### 思想 每一趟在后面n-i+1个中选出关键码最小的对象,作为有序列的第i个记录 #### 代码实现 ~~~c void SelectSort(SqList &K) { for (i=1; i<L.length; ++i) { //在L.r[i..L.length] 中选择key最小的记录 k=i; for( j=i+1;j<=L.length ; j++) if ( L.r[j].key < L.r[k].key) k=j; if(k!=i) L.r[i]←→L.r[k]; // 交换值 } } ~~~ #### 算法分析 最好情况移动0次,最坏移动3(n-1)次 比较1/2(n$^{2}$-n)次 时间复杂度O(n$^{2}$) 空间复杂度O(1) 稳定 ### 树形选择排序 在简单法上利用上次比较的结果,选取次最小者 ### 堆排序 满足下列要求  非终端结点的值均小于或大于左右子结点的值,堆顶元素(根)最小或最大 #### 思想 * 将无序序列建成一个堆(大根堆或者小根堆) * 输出对丁最大(小)值 * 使剩余的n-1个元素又调整成一个堆,则可得到n个元素的次小值 * 重复执行得到有序序列 **无序数组转换为大根堆**: 若孩子结点关键字值均小于父结点值,结束,若存在孩子结点值大于父结点值,将最大的孩子结点和父结点交换,并对孩子结点重复同样操作 **完成最终顺序结构排序:** 将顶端最大值和末尾值交换,此时对前n-1个重新调整并堆排序 #### 算法分析 **时间复杂度O(nlog$_{2}$ n) 空间复杂度O(1) 不稳定** 适用于n较大的情况 ## 归并排序 将两个或以上的有序表组合成一个新有序表 ### 排序过程 * 初始序列看成n个有序子序列,每个子序列长度为1 * 两两合并,得到[n/2]个长度为1或2的有序序列 * 再两两合并,重复至得到长度为n的有序序列为止 类似于双链表合并 ### 算法分析 **时间复杂度O(nlog$_{2}$n) 空间复杂度O(n) 稳定** ## 基数排序 不需要关键字之间的比较 多关键字排序,采用链表作为存储结构来排序 ### 最高位优先法 * 先对最高位关键字k1(如花色)排序,将序列分成若干子序列,每个子序列有相同的k1值; * 然后让每个子序列对次关键字k2(如面值)排序,又分成若干更小的子序列; * 依次重复,直至就每个子序列对最低位关键字kd排序,就可以得到一个有序的序列。 **十进制数比较可以看作是一个多关键字排序** ### 最低位优先法 * 首先依据最低位排序码kd对所有对象进行一趟排序 * 再依据次低位排序码kd-1对上一趟排序结果排序 * 依次重复,直到依据排序码k1最后一趟排序完成,就可以得到一个有序的序列 ### 链式基数排序 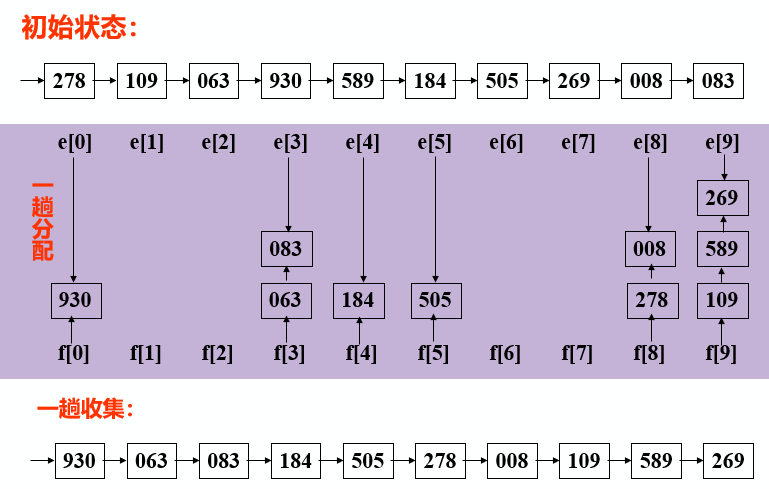 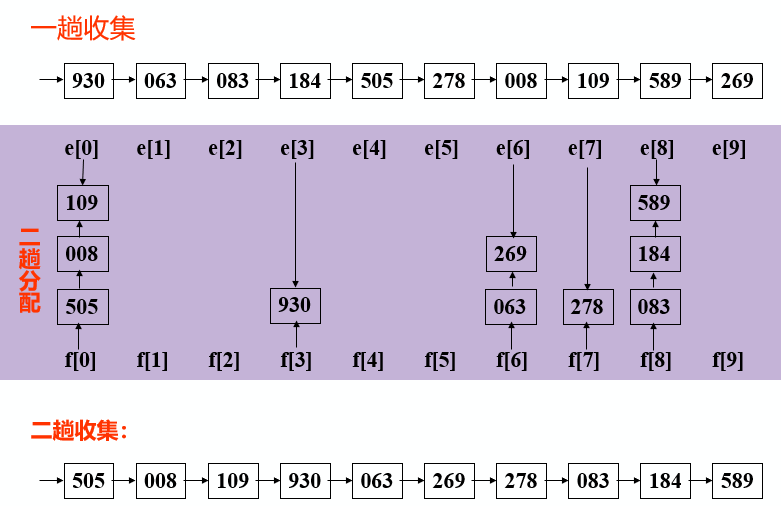 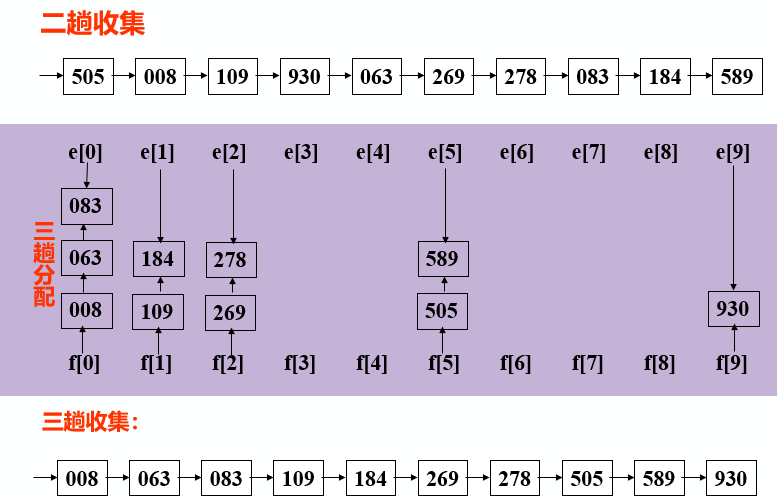 时间复杂度O(d(n+rd)) 空间复杂度O(n+rd) 稳定 ## 外部排序 1.按可用内存大小,利用内部排序方法,构造若干个记录的有序子序列写入外存,通常称这些记录的有序子序列为 “归并段”; 2.通过“归并”,逐步扩大(记录的)有序子序列的长度,直至外存中整个记录序列按关键字有序为止。 ## 总结 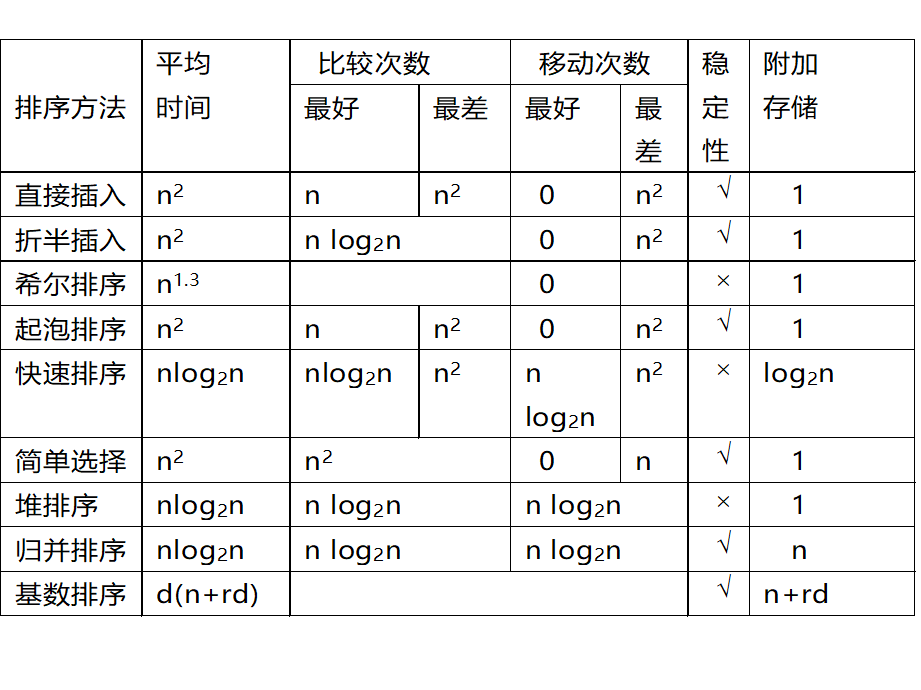 数据不是顺次后移导致方法不稳定 快速排序是基于比较的内部排序中平均性能最好的 基数排序时间复杂度最低,但对关键字结构有要求:指导各级关键字主次关系和取值范围 * 为避免顺序存储时大量移动记录的时间开销,可考虑用链表作为存储结构:直接插入排序、归并排序、基数排序 * 不宜采用链表作为存储结构的折半插入排序、希尔排序、快速排序、堆排序 n较大 * 分布随机,稳定性不做要求,则采用快速排序 * 内存允许,要求排序稳定时,则采用归并排序 * 可能会出现正序或逆序,稳定性不做要求,则采用堆排序或归并排序 n较小 * 基本有序,则采用直接插入排序 * 分布随机,则采用简单选择排序,若排序码不接近逆序,也可以采用直接插入排序 最后修改:2021 年 12 月 25 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
