Loading... # **Python~XPath** * **XML文档中搜索内容的一门语言** * **html是xml的一个子集** **lxml模块** **/a** **a标签** **/a/b** **a下b标签** **/a/b/text()** **a下b标签中的内容** **/a/b//c/text()** **a下b下所有c标签内容(不管b的下一级还是二级是c)** **/a/b/*/c/text()** **a下b下任意一级(span或者div之类的)下的c标签内容** **eg:** **/html/body/ol/li/a[@href='hello']** **找到特定的a标签** **/html/body/ol/li/a/@href** **找到特定的a标签中href内容** **F12可以右键复制相关元素完整XPath路径** **以猪八戒网为例学习XPath的爬虫使用** **地址:**[**【北京saas价格*****北京saas报价】*****北京saas服务外包信息-北京猪八戒网 (zbj.com)**](https://beijing.zbj.com/search/f/?kw=saas) ``` import requests from lxml import etree url = "https://beijing.zbj.com/search/f/?type=new&kw=saas" resp = requests.get(url) html = etree.HTML(resp.text) divs = html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div") # XPath路径得找准 print("\033[1;31;48mPrice\tTitle\tFirm\033[0m") for div in divs: price = div.xpath("./div/div/a[2]/div[2]/div[1]/span[1]/text()")[0].strip("¥") info = "saas".join(div.xpath("./div/div/a[2]/div[2]/div[2]/p/text()")) # 加上搜索的关键字 firm = div.xpath("./div/div/a[1]/div[1]/p/text()")[1].strip("\n\n") # 去除换行 print(price + '\t', end="") print(info + '\t', end="") print(firm) ``` **效果图**  **这里在定位信息模块时,会出现hl把搜索结果分割,最终在结果中显示的是含两个元素的列表** 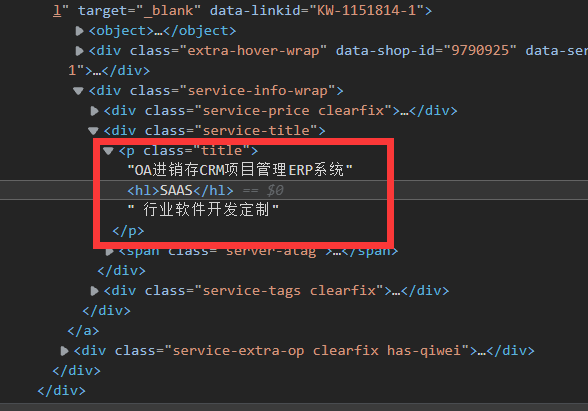 **没改前** 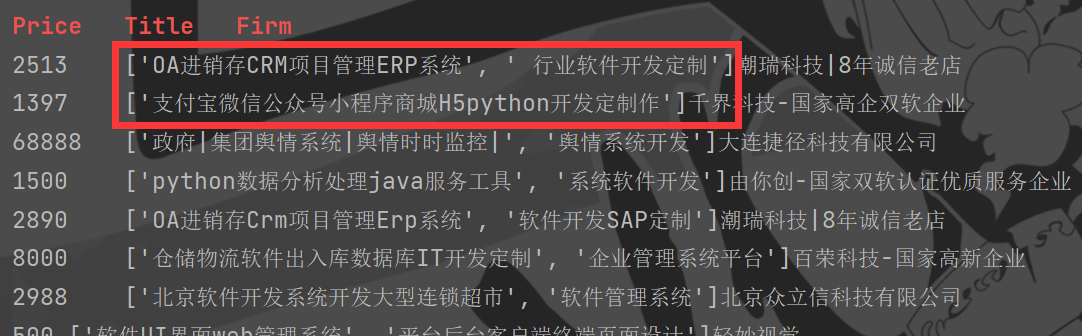 **所以需要使用join将列表里的元素连接起来,但有个bug,如果搜索结果在信息开头或结尾,就没法加上** 最后修改:2022 年 12 月 29 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
