Loading... # 数据挖掘1 ## Why 数据越来越多,但知识匮乏 **科学发展范式**:经验科学、理论科学、计算科学、数据科学 定义:从**数据**中提取**信息**和**知识**的过程 情报介于信息和知识之间 ## 主要内容 * 关联规则挖掘 * 非监督式机器学习——聚类:相似的放在一起,没有预先的模型 * 监督式机器学习 **分类**:学习建模-分类测试 **数值预测**:学习建模-数值预测 * 回归 ## 数据类型和统计 数据对象——实例、数据点、元组、对象 属性类型: * 标称:通常指类别、状态,特殊的二进制数据包含0和1属性 * 序数:排名、顺序等 * 区间:以单位长度顺序性度量,倍数无意义,如年份、温度等 * 比率:具有零点,乘法有效,比如长度、重量等 数据的中性化趋势:均值、中位数、众数 ## 数据可视化 ### 箱线图 <img src="http://xherlock.top/usr/uploads/2022/09/379846932.png" alt="image-20220908170706934" style="zoom: 50%;" style=""> 盒装图能够分析多个属性数据的离散度差异性 ### 直方图 分析单个属性在各个区间变化分布 <img src="http://xherlock.top/usr/uploads/2022/09/435527513.png" alt="image-20220908171159983" style="zoom:67%;" style=""> ### 散点图 正相关、负相关、不相关 可以预测也可以显示不同组数据的相关性分布 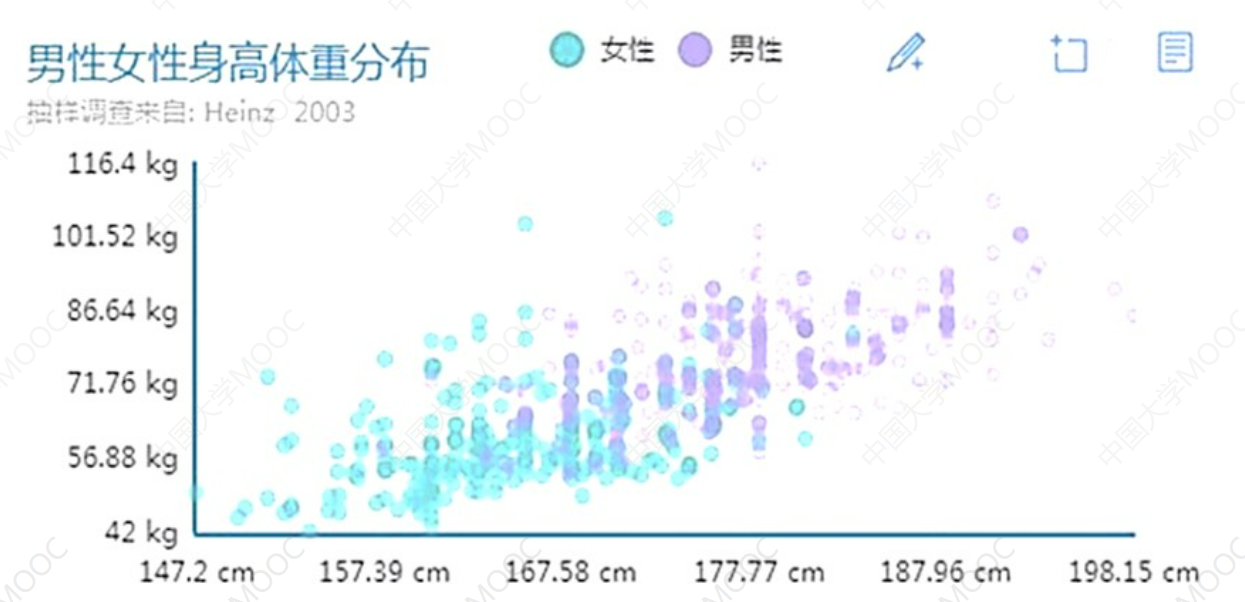 ## 数据预处理 ### 数据清洗 * 不完整:缺少属性值 * 含嘈杂的噪音,错误或离群:工资=-10 * 不一致的代码或不符的名称:曾经评级1、2、3,现在A、B、C **缺失数据怎么处理** * 忽略元组:类标号缺少时通常这么做 * 手动填写遗漏值:工作量大 * 自动填写:使用属性的平均值填充空缺值 **噪音数据处理**:箱线图找出删除掉 ### 数据集成 将来自多个数据源的数据组合成一个连贯的数据源 数据冲突时:对同一个真实世界的实体,来自不同源的属性值,可能单位尺度不同 整合数据时可能发生数据冗余:相同的属性或对象可能有不同的名字在不同的数据库中 **卡方测试**  **相关系数**  **协方差**  ### 数据规约 #### 降维 **降维**:降低数据复杂度,维数越多,数据越稀疏,淹没感兴趣数据 **降维原因**:类似神经网络的机器学习,主要需要学习各个特征的权值参数,特征越多,需要学习的参数越多,模型越复杂;机器学习训练集原则:模型越复杂,需要更多的训练集来学习模型参数,否则将模型欠拟合 **PCA主成分分析法**:将原来众多具有一定相关性的属性重新组合成一组相互无关的综合属性来代替原来的属性 #### 降数据 简单随机抽样: * 相等的概率选择 * 不放回抽样 * 有放回抽样 分层抽样: * 每组抽相同个数 * 用于偏斜数据 #### 数据压缩 ### 数据转换和离散化 #### 规范化方法 函数映射:给定的属性值更换了一个新的表示方法,每个旧值和新值可以被识别 规范化:按比例缩放到一个具体的区间 * 最小-最大规范化: $v'=\frac{v-min}{max-min}(new\_max-new\_min)+new\_min$ * z-分数规范化: $v'=\frac{v-mean}{\sigma}$,mean为均值,$\sigma$为标准差 * 小数定标规范化:移动属性的小数点位置,移动位数依赖于属性的最大值 #### 离散化方法 why:部分数据挖掘算法只使用于离散数据 * 等宽法:根据属性的值域来划分,使得每个区间的宽度相等 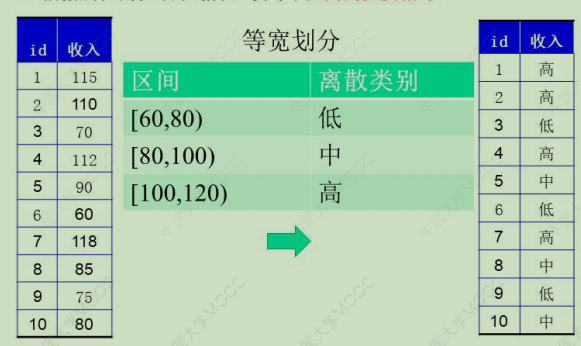 * 等频法:根据取值出现的聘书来划分,将属性的至于划分成多个小区间,并且要求落在每个区间的样本数目相等 * 聚类:将数据划分到不同的离散类别 最后修改:2022 年 10 月 02 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 1 如果觉得我的文章对你有用,请随意赞赏
