Loading... # Python爬取网页防盗链的视频 以梨视频网站为例学习绕过防盗链爬取下载视频 地址:[梨视频官网-做最好看的资讯短视频-Pear Video](https://pearvideo.com/) 首先看要爬取网站的一个视频页面 可以看到它是动态显示video文件链接的,网页源代码里放的只是图片 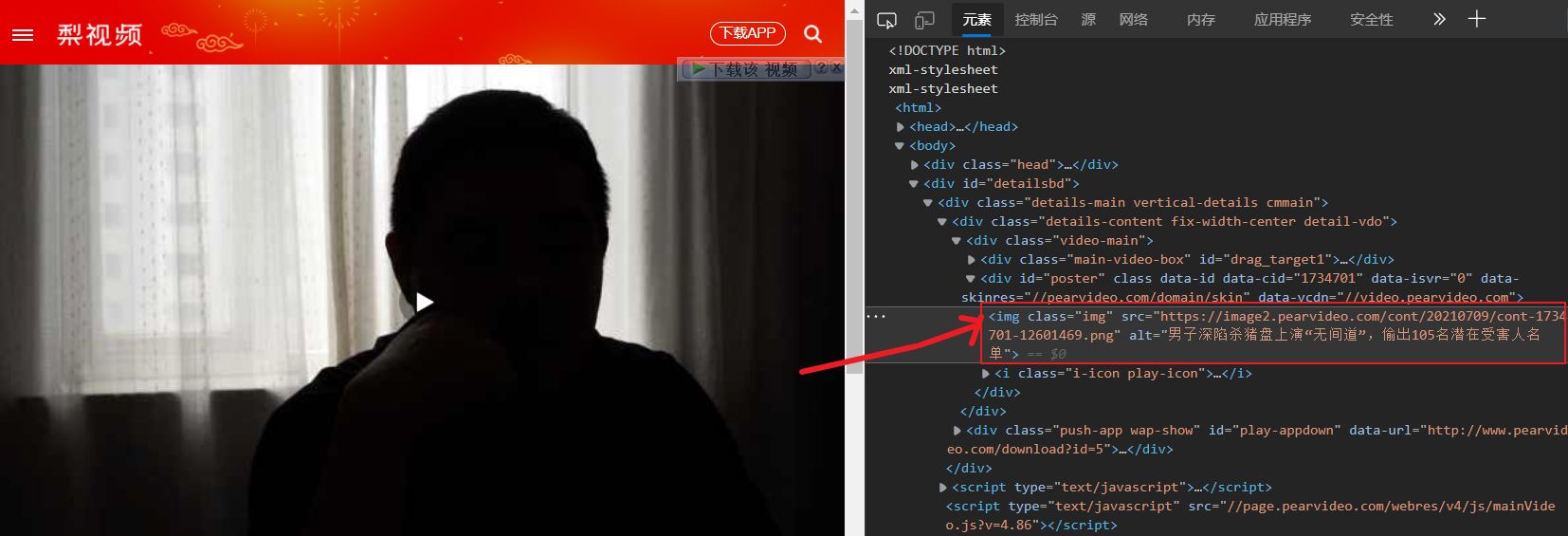 点击视频时查看网页网络情况 找到视频请求网址 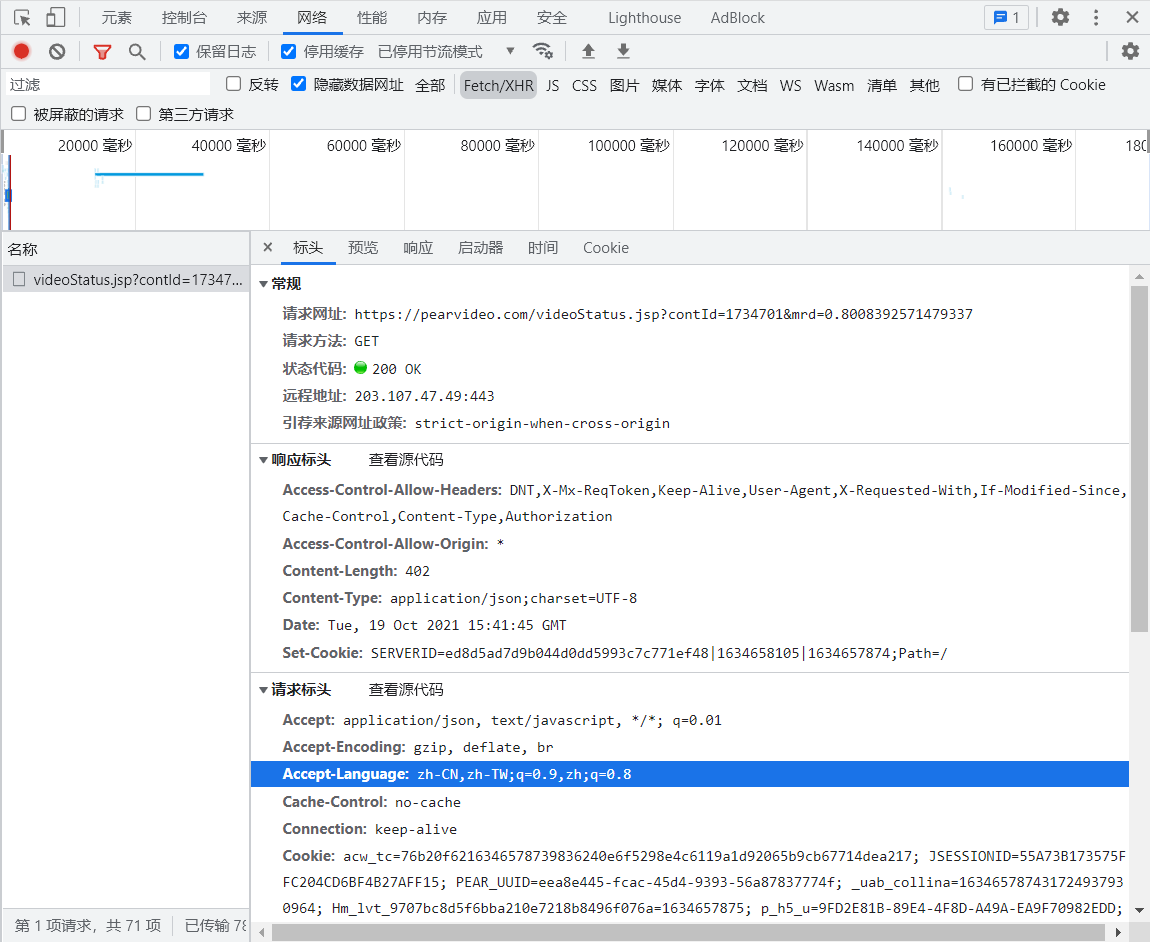 查看预览 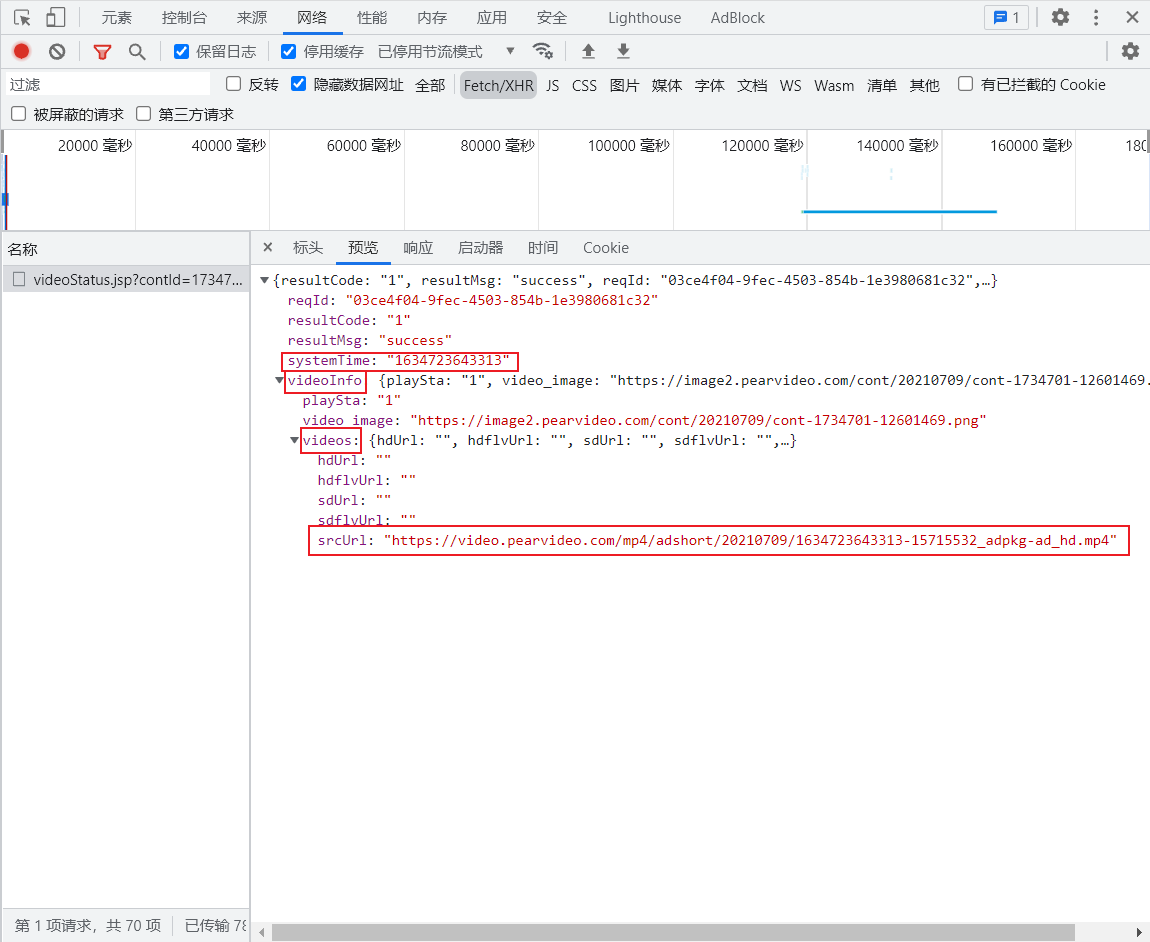 与点击播放后页面源代码中的视频地址比较 ~~~ https://video.pearvideo.com/mp4/adshort/20210709/cont-1734701-15715532_adpkg-ad_hd.mp4 ~~~ 可以看到是将最后一位的前面数字替换成了cont-1734701,而这串数字正是json上面的systemTime 而这个cont-后跟的正是我们前面看到的contId 因此最终网址可进行替换得到 代码如下 ```python # 1.拿到contId # 2.拿到videoStatus返回的json. -> srcURL import requests url = "https://pearvideo.com/video_1734701" contId = url.split("_")[1] headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36", # 防盗链:当前访问前的地址 "Referer": url } videoStatusUrl = f"https://pearvideo.com/videoStatus.jsp?contId={contId}&mrd=0.8008392571479337" resp = requests.get(videoStatusUrl, headers=headers) # print(resp.text) dic = resp.json() srcUrl = dic['videoInfo']['videos']['srcUrl'] systemTime = dic['systemTime'] srcUrl = srcUrl.replace(systemTime, f"cont-{contId}") # print(srcUrl) # 下载视频(写入文件) with open("a.mp4", mode="wb") as f: f.write(requests.get(srcUrl).content) ``` 最后修改:2022 年 12 月 29 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
