Loading... # 散列函数与消息鉴别 ## 散列函数 哈希函数,一种单向密码体制,从明文到密文的不可逆映射,只有加密过程,没有解密过程 散列函数作用:M(输入消息)⟶MD(消息摘要/散列码) 作用:生成文件或者其他数据块的“数字指纹” ### 性质 **基本特性** * h(m)算法公开,不需要密钥 * 具有数据压缩功能,可将任意长度的输入数据转换为一个固定长度的输出 * 对任何给定的m,h(m)易于计算 **安全性要求** * 单向性:给定散列值h(m),求得m在计算上不可行 * 弱抗碰撞性:对任意给定消息m,寻找与m不同的消息m'使得它们的散列值相等,在计算上不可行 * 强抗碰撞性:寻找任意两个不同的消息m和m',使得两者散列值相等,在计算上不可行 碰撞攻击:两个不同的消息产生了相同的哈希值(必然存在冲突) ### 应用 * 保证数据的完整性:验证散列码是否相等 * 单向数据加密:口令表存储散列值进行对比验证 * 数字签名:提高签名速度,不泄露原始消息 ## 散列函数的构造和设计 ### 简单的散列函数  特点:简单高效 攻击方法:第二原像攻击(不满足弱抗碰撞)  ### 迭代型散列函数 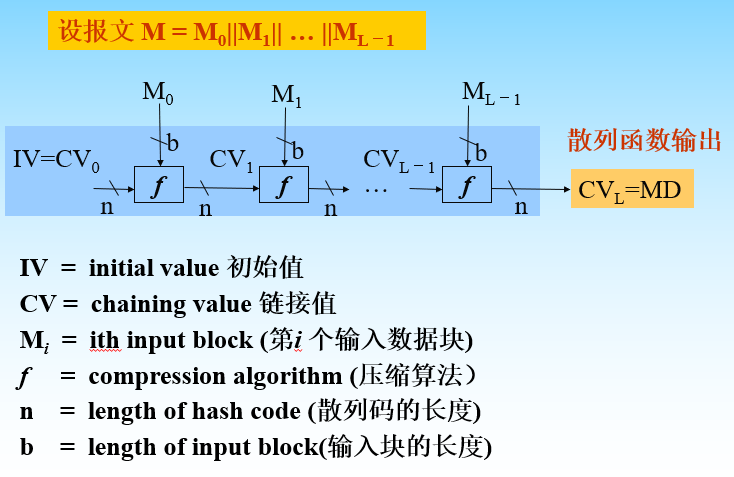 使用基于对称分组密码的CBC/CFB工作模式(使用公钥密码算法计算效率太低,无实用价值) 密钥k不能公开,否则会使得攻击者构造消碰撞十分容易 以CBC模式公开密钥下的攻击为例: 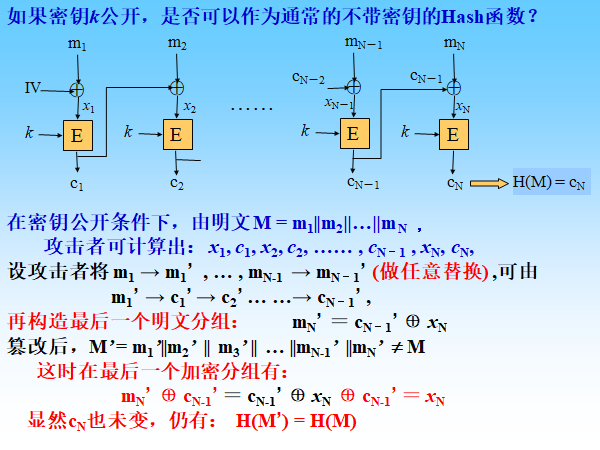 当然也有直接设计散列函数的,不基于任何假设和密码体制,通过构造复杂的非线性关系达到单向性要求(有MD2\~5、SHA系列) ## 安全散列算法SHA ### SHA1 NIST(美国国家标准与技术研究院)发布的数字签名标准DSS中使用的散列算法 大端存储 输入:最大长度为$2^{64}-1$位 输出:160位消息摘要 处理:输入以512位数据块为单位处理 1. 消息分割和填充 **最后一个报文分组** 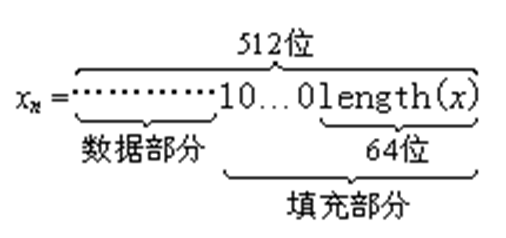 2. 初始化缓冲区:使用5个32位的字单元作为计算MD的缓存 A=67452301 B=EFCDAB89 C=98BADCFE D=10325476 E=C3D2E1F0 3. 以512位一组处理消息 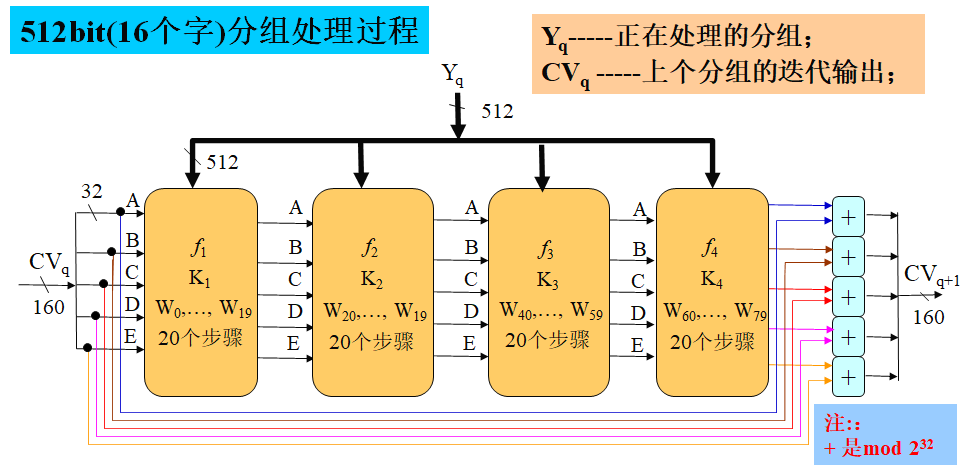 **SHA系列算法比较** | **算法** | **消息长度** | **分组长度** | **字长** | **散列值长** | **使用常数** | **基本函数** | **处理步骤** | | ---------- | -------------- | -------------- | ---------- | -------------- | -------------- | -------------- | -------------- | | SHA-1 | <264 | 512 | 32 | 160 | 4×32 | 4 | 80 | | SHA-256 | <264 | 512 | 32 | 256 | 64×32 | 6 | 64 | | SHA-384 | <2128 | 1024 | 64 | 384 | 80×32 | 6 | 80 | | SHA-512 | <2128 | 1024 | 64 | 512 | 80×32 | 6 | 80 | ## 对散列函数的攻击 ### 生日悖论和生日攻击 随机23人中,至少有两人生日相同的概率为0.5 实测如下(还真两次都出现相同生日的了)  转换成攻击描述:给定一个散列函数H(x),有n个可能的输出;若H有k个随机输入,问k必须取多大才能使至少存在一个碰撞的概率大于0.5  ## 消息鉴别 鉴别是指在两个通信者之间建立通信联系后,每个通信者对收到信息进行验证,以保证收到信息的真实性,确保: * 报文是由确认的发送方产生的 * 报文内容没有被篡改过 * 报文是按与发送时的相同顺序收到的 ### 基于加密技术的消息鉴别 #### 利用对称加密体制实现  局限性:需要接收方有某种方法能判定解密出的明文是否合法 #### 利用公钥密码体制实现 **提供消息鉴别** 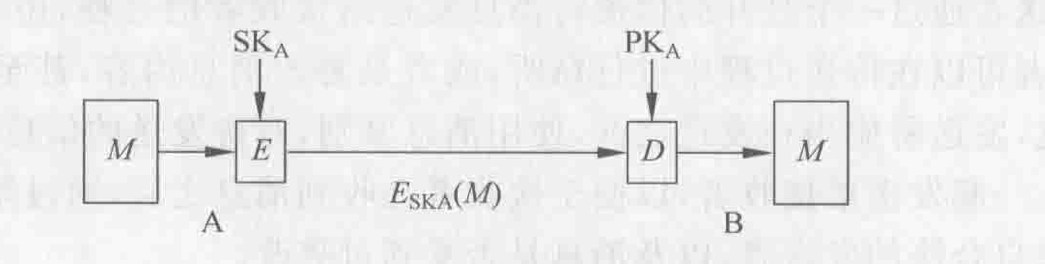 注意:发送方使用自己的**私钥**加密!!!(和正常公钥密码体制中用公钥加密不一样) 能够实现数字签名,抗抵赖,提供鉴别 **提供消息鉴别和机密性保护** 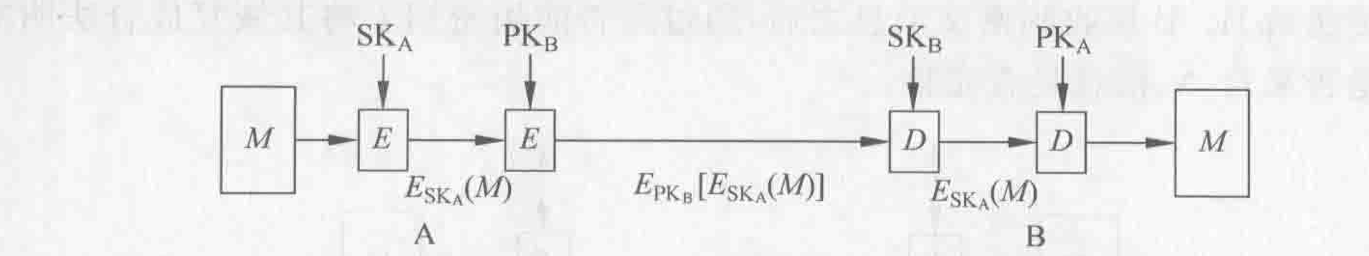 ### 基于散列函数的消息鉴别 #### 消息鉴别码 报文/消息鉴别码(MAC)用于提供数据原发鉴别和数据完整性的密码校验值 一个MAC算法由一个秘密密钥k和参数化的一簇函数hk构成,函数性质如下: * 容易计算 * 压缩:hk把任意具有有限长度的一个输入x映射成一个具有固定长度的输出hk(x) * 强抗碰撞性 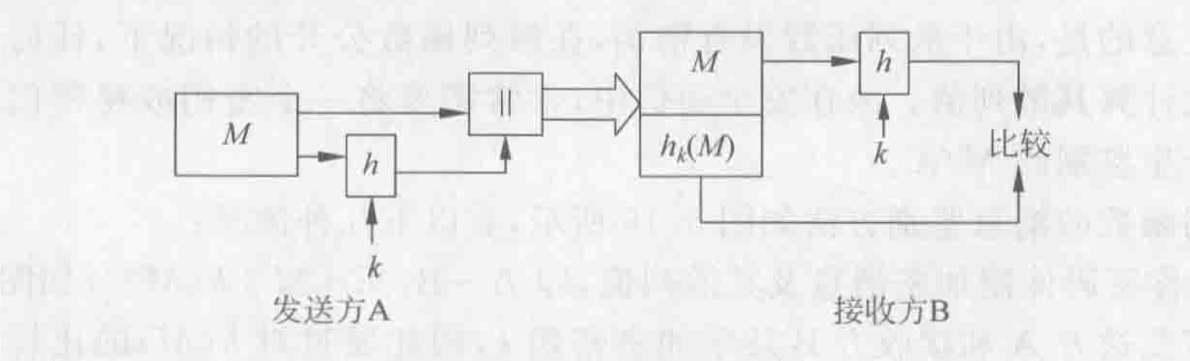 **MAC函数无需可逆**,因为整个过程中不需要解密 上图所示方法只能提供消息鉴别,不能提供机密性(消息以明文传输) *以下两种方式提供机密性* 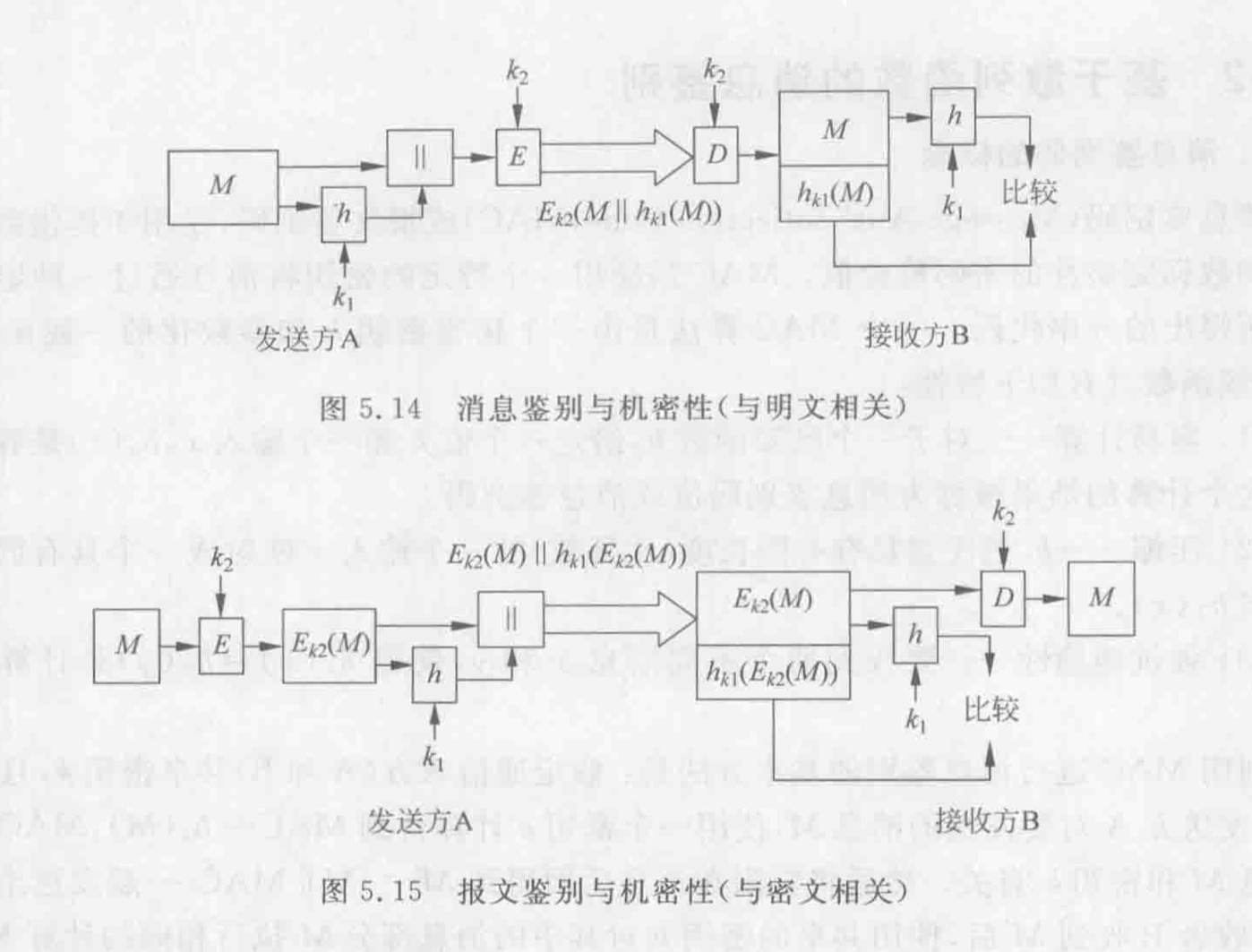 #### 基于散列函数的消息鉴别 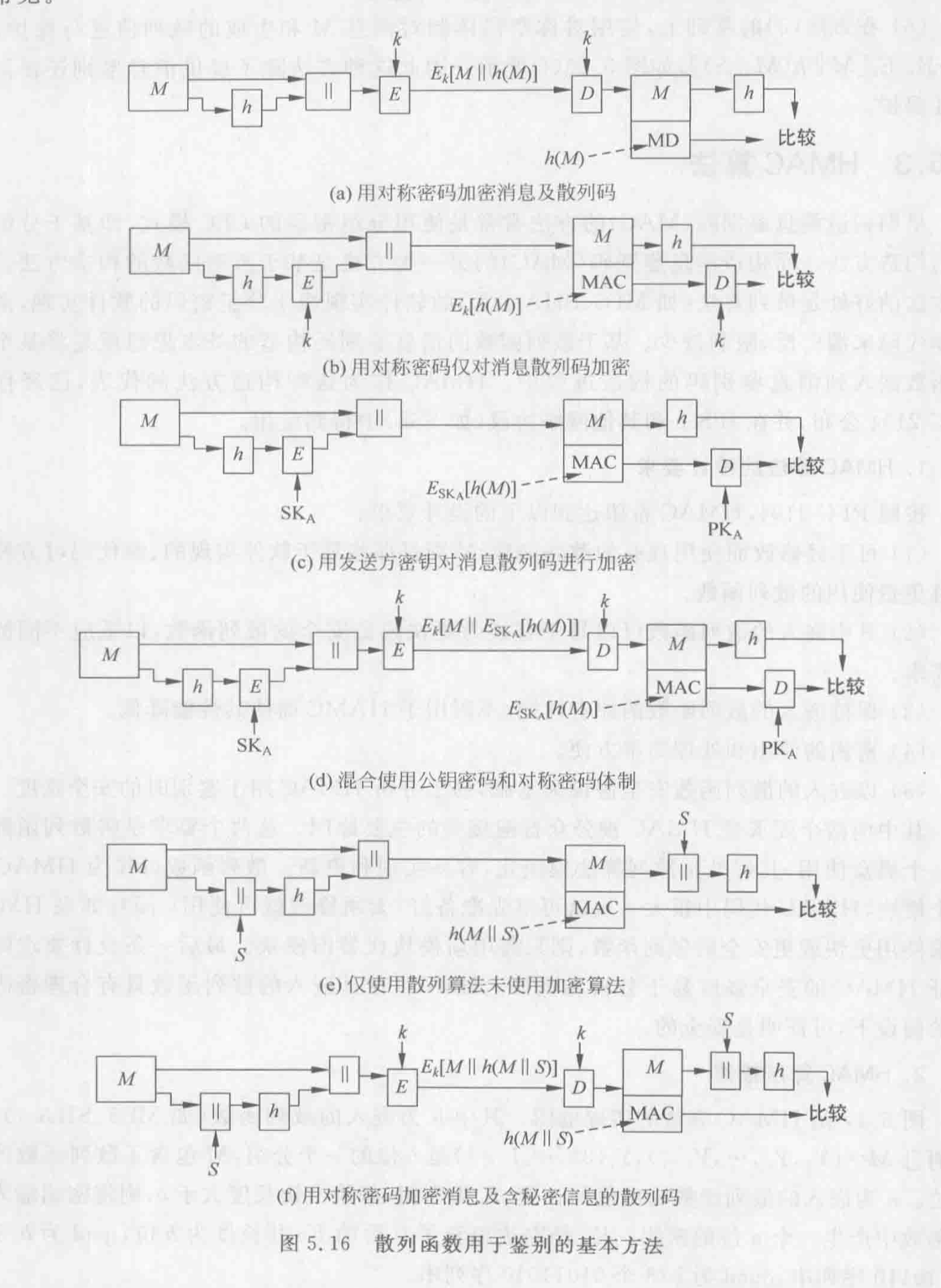 ### HMAC算法 带密钥的单向散列函数 最后修改:2022 年 06 月 04 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 3 如果觉得我的文章对你有用,请随意赞赏
