Loading... # 数据操作 Data Manipulation/Definition 结构化查询语言--SQL--关系数据库语言 ## SQL简介 数据库语言应允许用户 * 创建数据库和关系结构 * 对关系进行增删改查 * 完成简单或复杂的查询 * 数据库语言功能丰富、结构简洁、易学易用 * 易于移植 SQL包括**DDL**(数据定义语言,data definition language,定义数据库结构和数据的访问控制)和**DML**(数据操作语言,data manipulation language,用于检索和更新数据)、DCL SQL:非过程化(不需指定数据的访问方法)、无格式(空格、TAB不影响)、命令由英语单词组成 扩展的巴克斯范式(BNF)定义SQL语句 * 大写字母保留字 * 小写字母用户自定义字 * 竖线(|)表示从选项中选择 * 大括号表示所需元素 * 中括号表示可选元素 * 省略号表示某一项可选择重复0到多次 ## 数据操作 DML包括SELECT、INSERT、UPDATE、DELETE 注意区分数值型常量不带引号 ### 简单查询 ~~~sql SELECT [DISTINCT | ALL]{* | [columnExpression [AS newName]][,…]} FROM TableName [WHERE condition] [GROUP BY columnList][HAVING condition] [ORDER BY columnList] ~~~ \*替代所有列的名称;使用DISTINCT消除重复;选出**计算字段时字段必须是数值类型** 实现行选择使用WHERE子句 **比较运算符**:<>表示不等于,也可以!= **逻辑运算符**:NOT>AND>OR,计值由左至右 **范围查找条件**:BETWEEN/NOT BETWEEN,包含端点(最好还是通过比较表达式来取范围) **成员存在查找条件**:IN/NOT IN,测试数据是否与值表中的某一值相匹配,或测试数据是否不在指定的值表中 **模式匹配查找条件**:LIKE/NOT LIKE * %表示0或多个字符序列匹配 * _或?表示任意单个字符 * 若查找的字符串本身包含这两个模式匹配符,使用转义字符,如匹配'xher%lock'可以用 LIKE 'xher#%lock' ESCAPE '#' **空查找条件**:IS NULL/IS NOT NULL,测试空值时最好用这个 ### 查询结果排序(ORDER BY) ASC升序(默认),DESC降序,只能是SELECT语句的最后一个子句 **多列排序**:需要依次指定排序顺序 ### 聚集函数 ISO标准定义5个聚集函数,**只能用于SELECT和HAVING语句中** * COUNT:返回指定列中数据的个数,COUNT(DISTINCT)表示数出不同的个数 * SUM:返回指定列中数据的总和 * AVG:返回指定列中数据的平均值 * MIN:返回指定列中数据的最小值 * MAX:返回指定列中数据的最大值 ### 查询结果分组(GROUP BY) 按SELECT列表中的列进行分组,每一组产生一个综合查询结果。GROUP BY子句的列名又称为组列名 当使用GROUP BY时,SELECT列表中的项必须每组都有单一值 SELECT子句仅可包含 * 列名 * 聚集函数 * 常量 * 组合上述各项的表达式 SELECT子句中的所有列除非用在聚集函数中,否则必须在GROUP BY子句中,反之GROUP BY子句出现的列不一定出现在SELECT列表中 当WHERE子句和GROUP BY子句同时使用时,必须先使用WHERE子句,分组由满足WHERE子句查询条件的那些行产生。需注意空值被认为相等,即空值行分为一组 eg: ~~~sql SELECT branchNo,COUNT(staffNo) AS myCount, SUM(salary) AS mySum FROM Staff GROUP BY branchNo ORDER BY branchNo; ~~~ 由于a没出现在聚合函数中,所以必须出现在GROUP BY列表中 实际上相当于下面**嵌套查询** ~~~sql SELECT branchNo,(SELECT COUNT(staffNo) AS myCount FROM Staff s WHERE s.branchNo = b.branchNo), (SELECT SUM(salary) AS mySum FROM Staff s WHERE s.branchNo = b.branchNo) FROM Branch b ORDER BY branchNo; ~~~ **分组约束(Having子句)** 和ORDER BY一起使用限定哪些分组出现在最终查询结果中 WHERE是将行进行过滤,而HAVING是将分组进行过滤(使用的列明必须出现在GROUP BY字句列表中,或包括在聚集函数中,实际上HAVING子句中至少有一个聚集函数,否则直接用WHERE过滤就好了) 以上面例子扩充,选出员工数大于1的分公司 ~~~sql SELECT branchNo,COUNT(staffNo) AS myCount, SUM(salary) AS mySum FROM Staff GROUP BY branchNo HAVING COUNT(staffNo)>1 ORDER BY branchNo; ~~~ ### 子查询 SELECT语句完全嵌套到另一个SELECT语句中,内部SELECT语句(子查询)的结果用在外部语句中以决定最后的查询结果 **用于相等判断的子查询** ~~~sql SELECT staffNo,fName,INmae,position FROM Staff WHERE branchNo = (SELECT branchNO FROM Branch WHERE street = '163 Main St'); ~~~ **用于聚集函数的子查询** ~~~sql SELECT staffNo,fName,INmae,position,salary-(SELECt AVG(salary) FROM Staff) AS salDiff FROM Staff WHERE salary > (SELECT AVG(salary) FROM Staff); ~~~ 子查询应遵循 * ORDER BY子句不能用于子查询,外面的SELECT可以 * 子查询SELECT列表必须由单个列名或表达式组成,除非子查询使用了关键词EXISTS * 默认情况下,子查询中列名取自子查询的FROM子句中给出的表,也可通过限定列名的方法指定取自外查询的FROM子句中的表 * 当子查询是比较表达式中的一个操作数时,子查询必须出现在表达式的右边 eg:(SELECT AVG(salary) FROM Staff) < salary 错误 **嵌套子查询:IN的使用** ~~~sql SELECT staffNo,fName,INmae,position FROM Staff WHERE branchNo IN (SELECT branchNO FROM Branch WHERE street = '163 Main St'); ~~~ ### ANY与ALL 查询高于分公司B003中至少一位员工的工资的所有员工 ANY/SOME ~~~sql SELECT staffNo,fName,INmae,position,salary FROM Staff WHERE salary>SOME(SELECT salary FROM Staff WHERE branchNo='B003'); ~~~ 查询高于分公司B003中所有员工的工资的所有员工 ~~~sql SELECT staffNo,fName,INmae,position,salary FROM Staff WHERE salary>ALL(SELECT salary FROM Staff WHERE branchNo='B003'); ~~~ NOT IN等价于<> ALL ### 多表查询 要把来自多个表的列组合到结果表时,需要用到**连接**操作,SQL连接操作通过配对相关行来合并两个表中的信息,构成连接表的配对行指这两行在两个表的匹配列上具有相同的值 连接操作中,FROM子句列出多个表名,之间用逗号分开;通常还要用WHERE子句指明连接列 **简单连接** ~~~sql SELECT c.clientNo,fName,IName,propertyNo,comment FROM Client c,Viewing v WHERE c.clientNo=v.clientNo; ~~~ SQL标准提供了其他方式来指定连接 * FROM Client c JOIN Viewing v ON c.clientNo=v.clientNo(产生两个clientNo列) * FROM Client JOIN Viewing USING clientNo(实际使用中可能报错) * FROM Client NATURAL JOIN Viewing  两个表的连接查询不适用WHERE子句时,相当于两个表的**笛卡尔乘积**,存在WHERE子句时对乘积表中的每一行运用查找条件; **外连接** 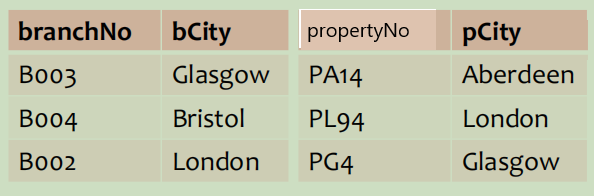 先看(内)连接 ~~~sql SELECT b.*,p* FROM Branch1 b,PropertyForRent1 p WHERE b.bCity=p.pCity; ~~~ 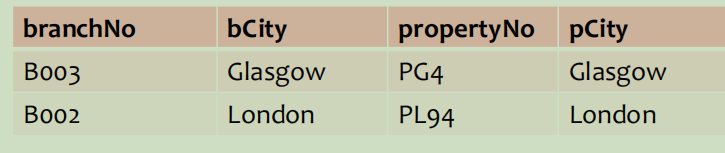 外连接保留不满足连接条件的行 *左外连接*:列出所有分公司以及与其处于同一城市的房产 ~~~sql SELECT b.*,p* FROM Branch1 b LEFT JOIN PropertyForRent1 p ON b.bCity=p.pCity; ~~~ 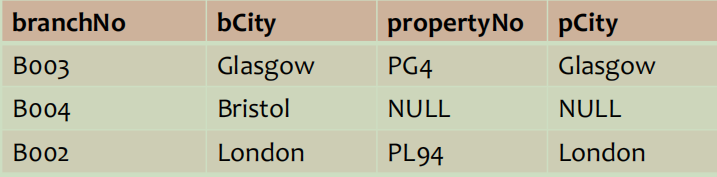 如图可知B004公司无房产 *右外连接* ~~~sql SELECT b.*,p* FROM Branch1 b RIGHT JOIN PropertyForRent1 p ON b.bCity=p.pCity; ~~~ 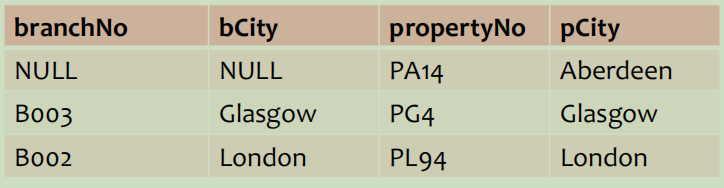 如图可知房产为PA14的无对应公司 *全外连接* ~~~sql SELECT b.*,p* FROM Branch1 b FULL JOIN PropertyForRent1 p ON b.bCity=p.pCity; ~~~ 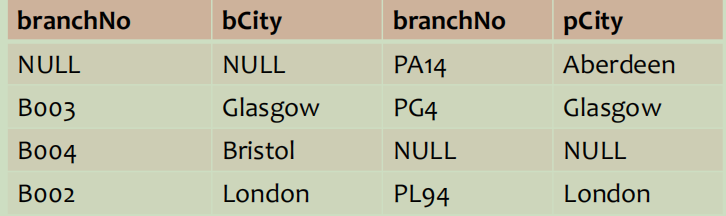 如图可以看出来就是上面左右外连接的合并 ### EXISTS和NOT EXISTS 仅用于子查询,EXISTS为真当且仅当子查询返回的结果表至少存在一行,**NOT EXISTS**正相反 相当于每条主查询的结果去子查询里进行验证True显示,FALSE不显示,等价于WHERE过滤条件  ### 合并结果表(UNION、INTERSECT和EXCEPT) UNION:并 INTERSECT:交 EXCEPT:差 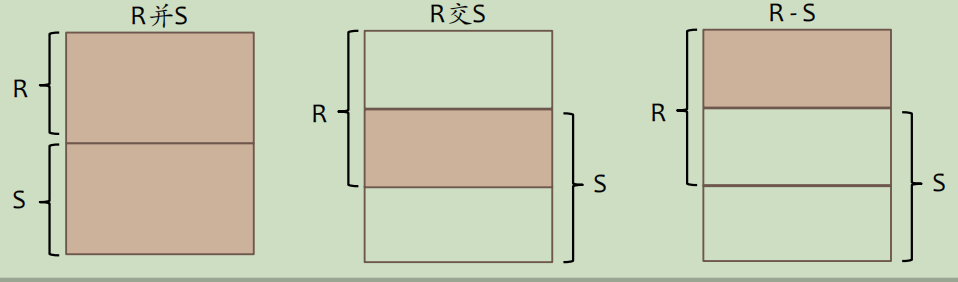 集合操作子句格式: operator \[ALL\][CORRESPONDING [BY \{column1 [,…]\}]] * 指定CORRESPONDING BY,则集合操作就在给定的列上执行 * 指定CORRESPONDING 而没有BY子句,则集合操作在两表共同的列上执行 * 指定ALL,则查询包括一切重复的行 **UNION** ~~~sql (SELECT city FROM Branch WHERE city IS NOT NULL) UNION (SELECT city FROM PropertyForRent WHERE city IS NOT NULL); ~~~ 或 ~~~sql (SELECT * FROM Branch WHERE city IS NOT NULL) UNION CORRESPONDING BY city (SELECT * FROM PropertyForRent WHERE city IS NOT NULL); ~~~ INTERSECT和EXCEPT同理 ### 数据库更新 * INSERT:向表中添加新的行 * UPDATE:修改表中现有的行 * DELETE:删除表中已有的行 **INSERT** ~~~sql INSERT INTO TableName [(columnList)] VALUES (dataValueList) ~~~ 插入时表名后最好带上列名(columnList),以便更好地对应,还要注意插入的数据格式 **IESERT…SELECT…**,注意对应数据 ~~~sql INSERT INTO StaffPropCount (SELECT s.staffNo, fName, lName, COUNT(*) FROM Staff s, PropertyForRent p WHERE s.staffNo = p.staffNo GROUP BY s.staffNo, fName, lName) UNION (SELECT staffNo, fName, lName, 0 FROM Staff WHERE staffNo NOT IN (SELECT DISTINCT staffNo FROM PropertyForRent)); ~~~ **UPDATE** ~~~sql UPDATE TabelName SET columnName1=dataValue1 [,columnName2=dataValue2…] [WHERE searchCondition] ~~~ 无条件时更新所有行 **DELETE** ~~~sql DELETE FROM TableName [WHERE searchCondition] ~~~ 最后修改:2022 年 05 月 30 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 2 如果觉得我的文章对你有用,请随意赞赏
