Loading... # **Python爬取壁纸** **以3G壁纸网为例学习bs64爬取并下载壁纸,地址:**[**电脑桌面壁纸大全-高清电脑桌面壁纸图片-超高清壁纸桌面免费下载-3g壁纸 (3gbizhi.com)**](https://desk.3gbizhi.com/) **首先看要爬取的图片名**  **ctrl+U查看源代码锁定代码块** 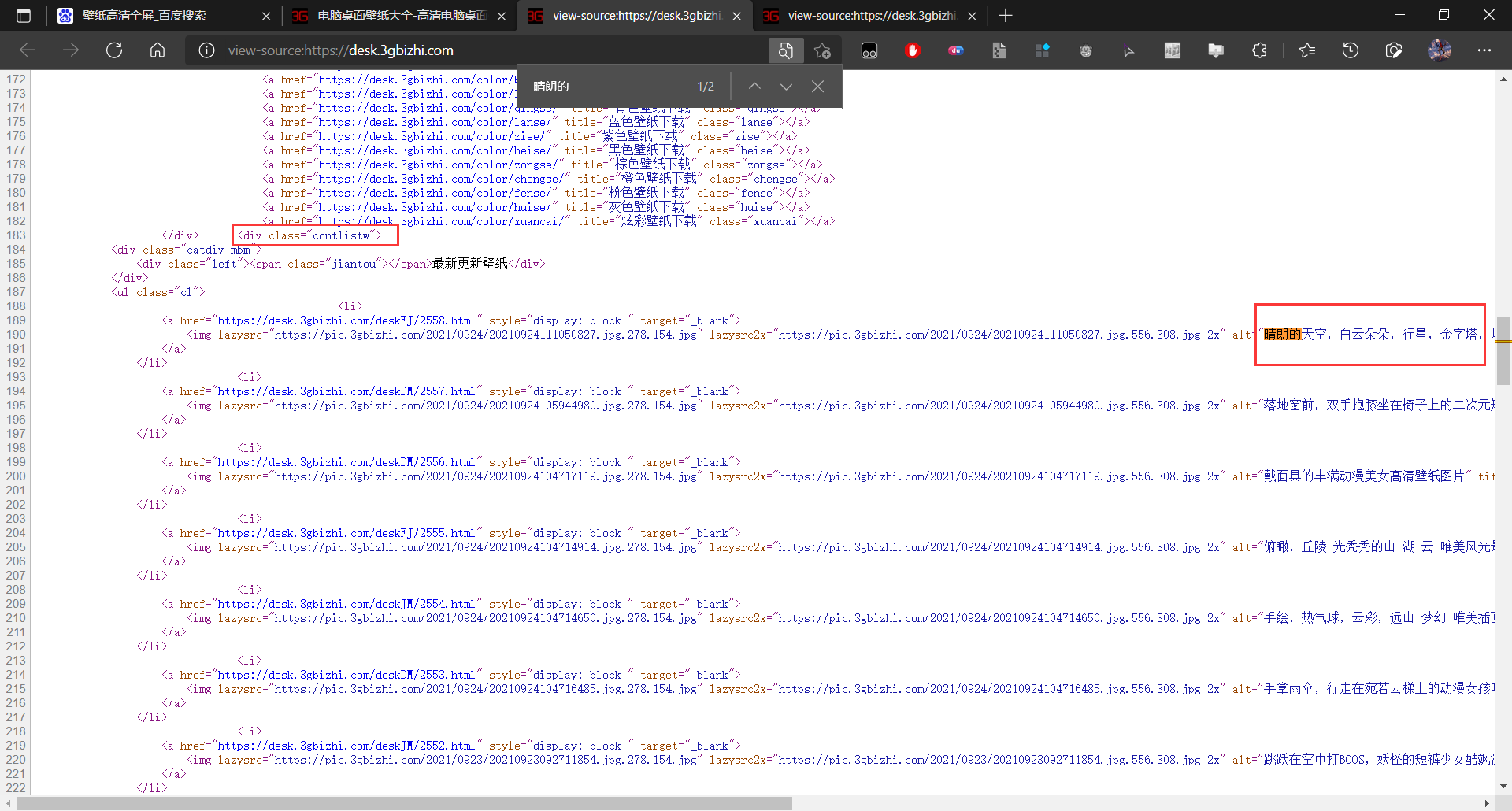 **选取div 下的contlistw的class属性读取,找到这个div中包含的所有a标签** ``` main_page = BeautifulSoup(resp.text, "html.parser") alist = main_page.find("div", class_="contlistw").find_all("a") ``` **for循环进入a标签中获取href中的子页面路径** ``` for a in alist: href = a.get('href') child_page_resp = requests.get(href) child_page_resp.encoding = 'utf-8' child_page_text = child_page_resp.text ``` **以第一个子页面为例,对壁纸进行定位** 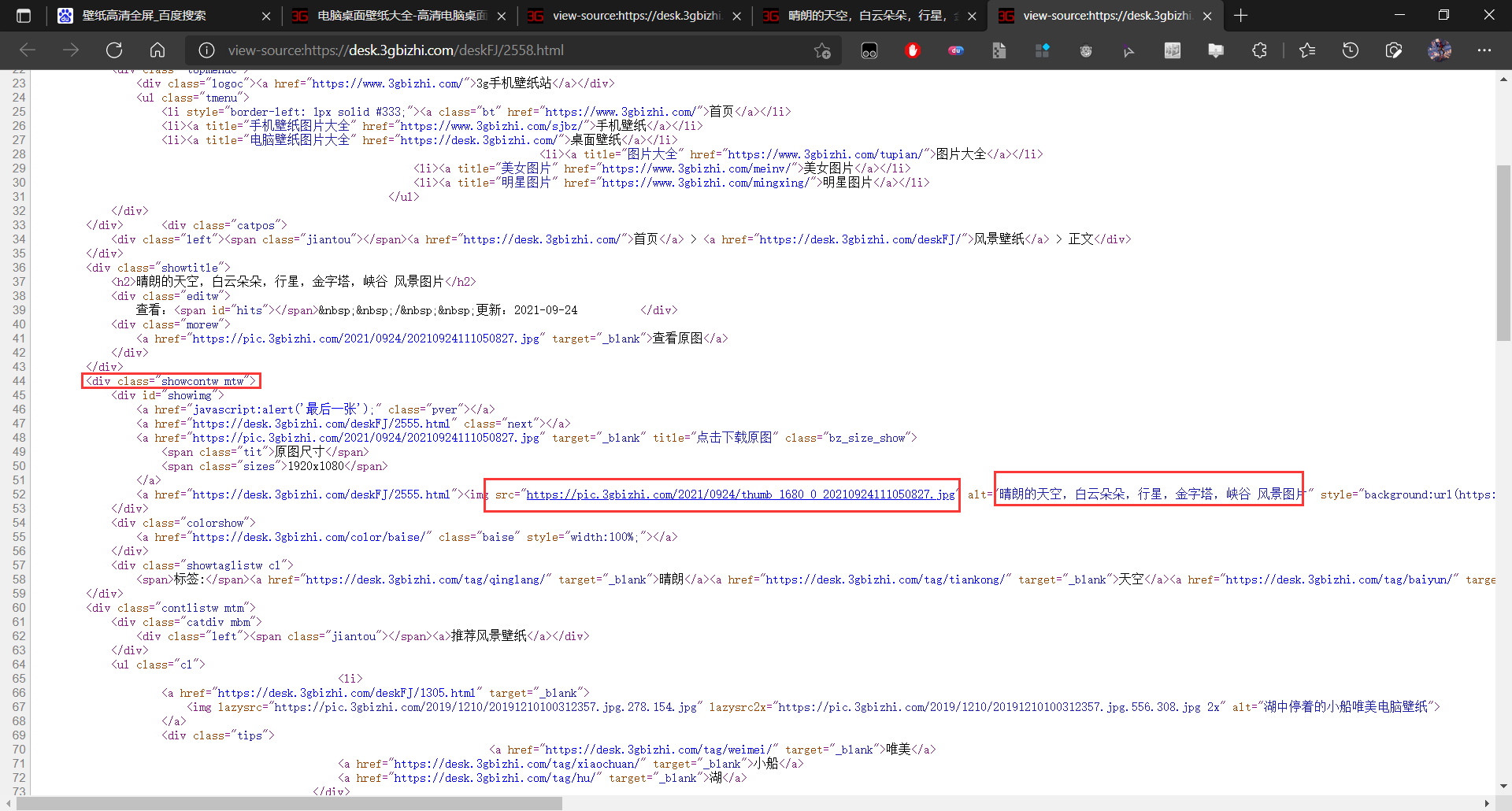 **选取div 下的showcontw mtw的class属性读取,找到这个div中包含的所有img标签** ``` child_page = BeautifulSoup(child_page_text, "html.parser") showing = child_page.find("div", class_="showcontw mtw") ``` **接下来抛出一些读取错误,因为首页后面还有跟contlistw属性一样的部分,导致没能读取壁纸而报错** ``` try: img = showing.find("img") src = img.get("src") except AttributeError as e: continue ``` **最后获取图片路径并将字节写入文件** ``` img_resp = requests.get(src) img_name = str(i) + ".jpg" with open("image/" + img_name, mode="wb") as f: f.write(img_resp.content) ``` **命名后放入当前目录下的image文件夹中** **完整代码如下:** ``` import time import requests from bs4 import BeautifulSoup url = "https://desk.3gbizhi.com/" resp = requests.get(url) resp.encoding = 'utf-8' main_page = BeautifulSoup(resp.text, "html.parser") alist = main_page.find("div", class_="contlistw").find_all("a") i = 1 for a in alist: href = a.get('href') child_page_resp = requests.get(href) child_page_resp.encoding = 'utf-8' child_page_text = child_page_resp.text child_page = BeautifulSoup(child_page_text, "html.parser") showing = child_page.find("div", class_="showcontw mtw") try: img = showing.find("img") src = img.get("src") except AttributeError as e: continue img_resp = requests.get(src) img_name = str(i) + ".jpg" with open("image/" + img_name, mode="wb") as f: f.write(img_resp.content) print("Over!!!", img_name) time.sleep(1) i = i + 1 print("All over!") ``` **效果图:** **网站首页的20张壁纸**  **我爬下来的壁纸,不多不少也是20张** 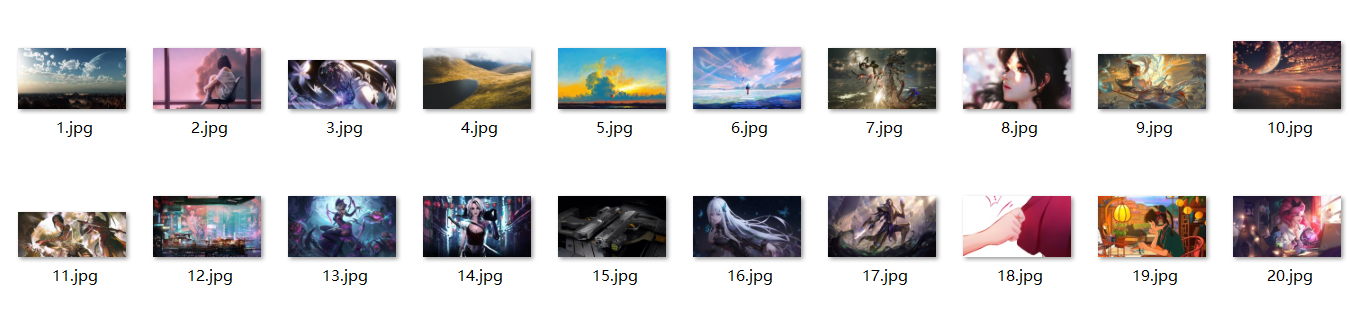 最后修改:2022 年 12 月 29 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
