Loading... # 机组~一个简单的计算机模型MARIE ## CPU基本知识和组织结构 CPU负责读取(fetch)程序指令,并对读取的指令进行译码(decode),然后在正确的数据上执行(execute)规定的操作序列  ### 寄存器(register) CPU内部的数据存储单元——通用寄存器可使用D触发器(D flip-flops)实现 存储数据、地址和控制信息 ### 算术逻辑单元(ALU,arithmetic logic unit) 执行逻辑运算和算术运算,一般有2个数据输入和1个数据输出 ### 控制单元(The Control Unit) * 负责监视所有指令的执行和各种信息的传输过程 * 负责从存储器中提取指令,对指令进行译码,确保数据适时的出现在正确地方 * 负责通知ALU使用哪一个寄存器,执行哪个中断、选择正确的电路 * 使用**程序计数器**寻找下一条要执行的指令 * 使用一个状态寄存器来存放某些特殊的操作状态(eg:溢出、进位、借位等) ### 总线(bus) 一组连线的集合,CPU通过总线与其他组件进行通信 连接方式: 1. 点对点总线:连接两台特定设备 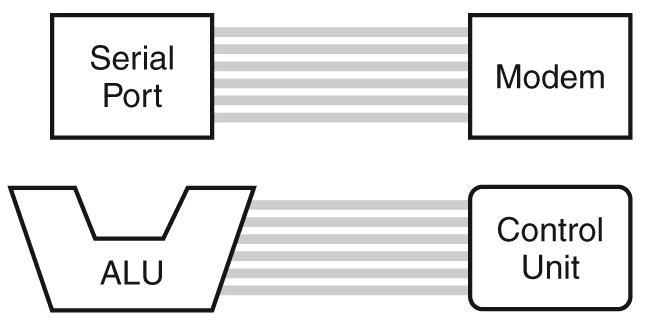 2. 多点总线:将总线用作一条公用通道来连接多个设备 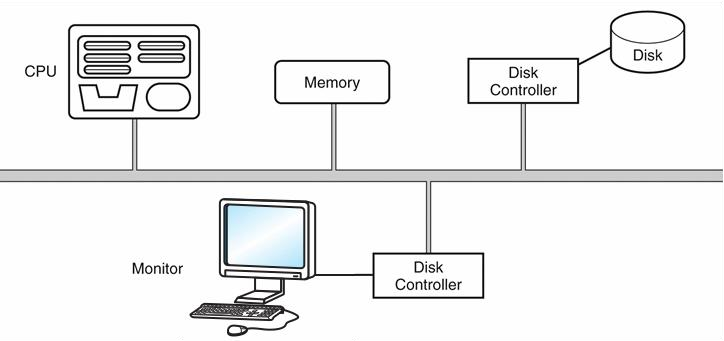 包含数据线、地址线、控制线、电源线的典型总线: 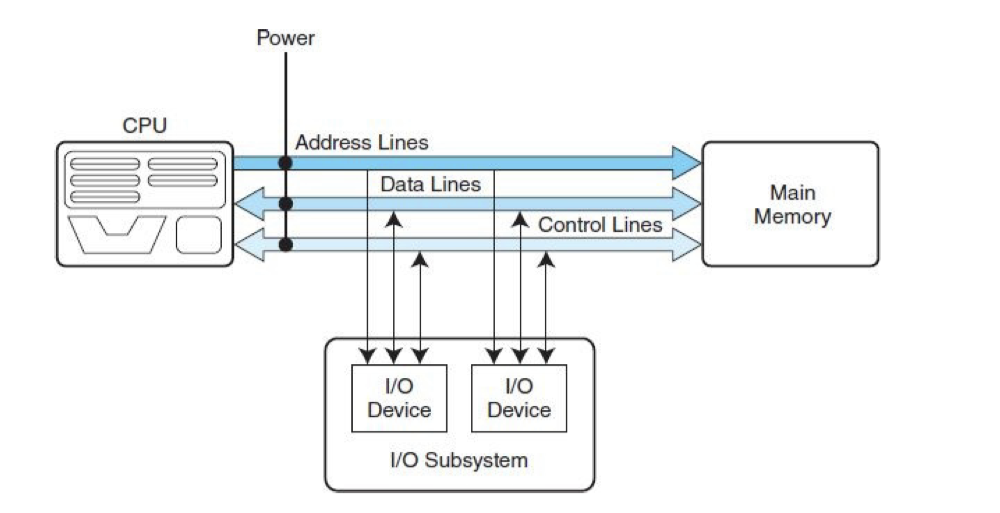 每个类型的传输发生在一个总线周期里,`总线周期`是完成总线信息传送所需的时钟脉冲间隔 对于有多个主控设备的的系统,需要总线仲裁机制(为某些主控设备设定一种优先级别) 1. 菊花链仲裁方式(Daisy chain arbitration):所有设备公用一个控制线发送请求,控制许可按优先级从高到低传输,方案简单但不公平 2. 集中式并行仲裁方式(centralized parallel arbitration):由一个中央仲裁控制器根据优先级进行仲裁,所有设备和中央控制器之间有两个控制线,分别发送请求和接收控制许可(eg:PCI总线),可能会导致瓶颈 3. 自选择的分配式仲裁方式(Distributed arbitration using self-selection):每个设备有一个独立的控制线用于发送请求,按优先级从高到低排列,第i+1个设备监听了前i个设备的请求控制线,若前i个设备没有发送请求时,第i+1个设备发送了请求,其获得总线控制许可 4. 冲突检测的分配式仲裁方式(Distributed arbitration using collision-detection):所有设备共享同一个控制线,若总线检查到任何冲突(多个同时请求),则设备必须发出另一个请求(eg:以太网) ### 时钟(Clocks) * 每台计算机至少包含一个时钟来同步(synchronize)其组件的活动 * 执行CPU的每条指令都是使用固定的时钟脉冲数目的,因此指令的性能通常是通过时钟周期(clock cycle time)的数目来测量 * 时钟频率(MHz、GHz为单位)决定了所有操作的执行速度 * 运行程序所需CPU时间:  ### I/O子系统 通过I/O设备与计算机进行通信,与主存储器之间进行数据交换,通常不与CPU直接相连,而是采用某种接口来处理数据交换 常见连接方式: * 存储器映射的I/O(memory-mapped):速度比较快,但需要使用大量内存空间 * 基于指令的I/O(instruction-based):必须使用支持对应指令集的CPU ### 存储器的组成和寻址 计算机内存由一组可寻址存储单元组成,这些单元类似于寄存器 内存可以按字节寻址,或者按字寻址 存储器(memory)由**随机存取存储器**(RAM)芯片构成 交叉存储器interleaved memory可以更加高效地访问 eg: 存储器:16 2K × 8bit chips,可以存储32K,需要15位来存储,4位选择哪个芯片,11位选择数据的偏移量 <img src="http://xherlock.top/usr/uploads/2022/03/392533415.png" alt="image-20220309170904008" style="zoom:80%;" style=""> 现假设有8个模块组成的按字节寻址的存储器,每个模块有4个字节,需要五位来唯一标识每个字节 **高位交叉** 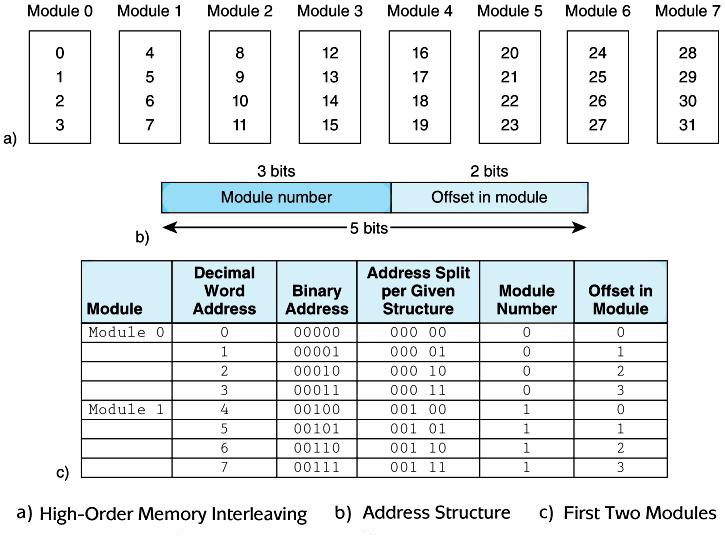 **低位交叉** 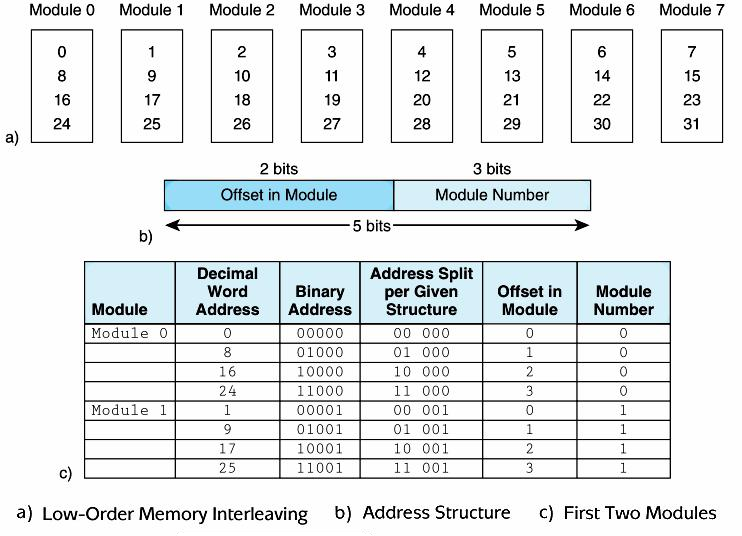 ### 中断 当高优先级时间发生,程序的正常执行就会改变,称为中断 中断可由I/O请求、算数错误(除以0)、非法指令、硬件故障、用户定义的中断点(程序调试)等触发 ## MARIE模型 The Machine Architecture that is Really Intuitive and Easy ### 组织结构 特点 * 2的补码表示 * 采用存储程序架构,16位固定字长的数据和指令 * 16位指令包括4位操作码(opcode)和12位地址码 * 内存采用按字寻址,可寻址4K(12位地址码得出)个存储位置 * 包含一个16位的算术单元 * 有7个寄存器 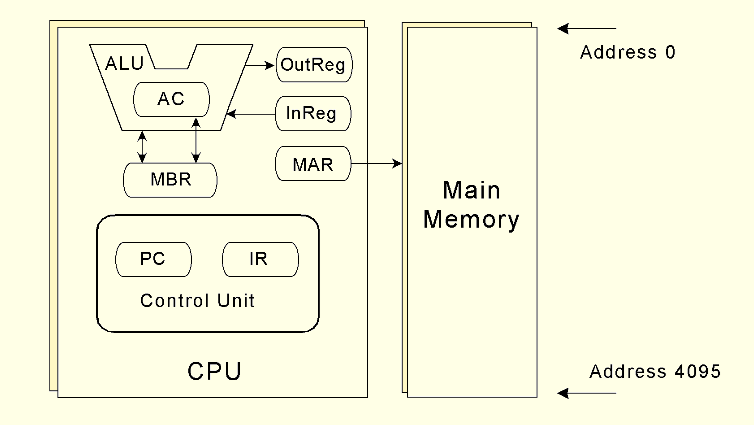 ### 寄存器和总线 7个寄存器: | abbr | EN | CN | bit | Function | | -------- | ------------------------- | ------------------ | ----- | ---------------------------------------- | | AC | Accumulator | 累加寄存器 | 16 | 存储指令运算操作数和运算结果 | | MAR | Memory address register | 存储器地址寄存器 | 12 | 保存所引用数据的存储器地址 | | MBR | Memory buffer register | 存储器缓冲寄存器 | 16 | 保存从存储器读取或将要写入存储器的数据 | | PC | Program counter | 程序计数器 | 12 | 保存程序将要执行的下一条指令的地址 | | IR | Instruction register | 指令寄存器 | 16 | 保存将要执行的下一条指令 | | InREG | Input register | 输入寄存器 | 8 | 保存来自输入设备的数据 | | OutREG | Output register | 输出寄存器 | 8 | 保存要输出到输出设备的数据 | MARIE data path <img src="http://xherlock.top/usr/uploads/2022/03/2362867676.png" alt="image-20220309173603600" style="zoom:80%;" style=""> ### 指令集架构(ISA:instruction set architecture) 机器的指令集架构指定了计算机可以执行的指令和格式,本质上是软件和硬件间的接口 format: 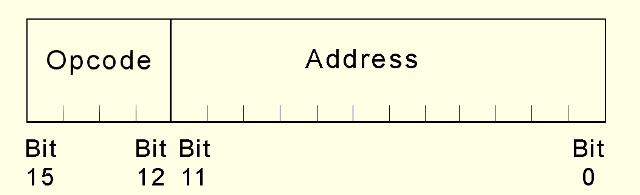 fundamental instructions:  每个指令都涉及多个操作,称其为微操作:描述微操作行为的符号表示法称为**寄存器传输表示法**(RTN)或**寄存器传输语言**(RTL) 使用notation(符号)**M[X]**表示存储在存储器位置X中的实际数据,符号$\leftarrow$表示信息的传送 RTL for **Load X** $MAR\leftarrow X$ $MBR \leftarrow M[MAR]\\$ $AC \leftarrow MBR$ **地址X 必须先读取到MAR** RTL for **Store X** $MAR \leftarrow X$ $MBR \leftarrow AC$ $M[MAR] \leftarrow MBR$ RTL for **Add X** $MAR \leftarrow X$ $MBR \leftarrow M[MAR]$ $AC \leftarrow AC + MBR$ RTL for **Subt X** $MAR \leftarrow X$ $MBR \leftarrow M[MAR]$ $AC \leftarrow AC - MBR$ RTL for **Input** $$ AC \leftarrow InREG $$ RTL for **Output** $$ OutREG \leftarrow AC $$ RTL for **Skipcond**  ## 指令的执行过程 fetch-decode-execute(取值-译码-执行) 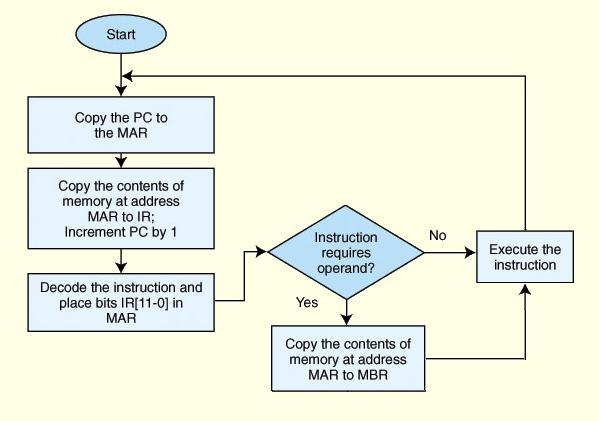 中断:停止上面周期的正常流程,转去执行其他操作 先判断是否产生中断: 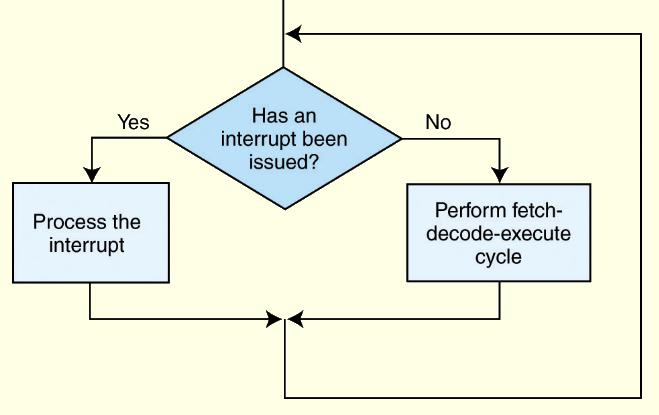 若中断:(ISR,Interrupt Service Routine中断服务程序)  ## 一个简单的程序 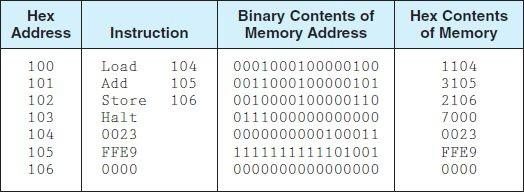 LOAD 104 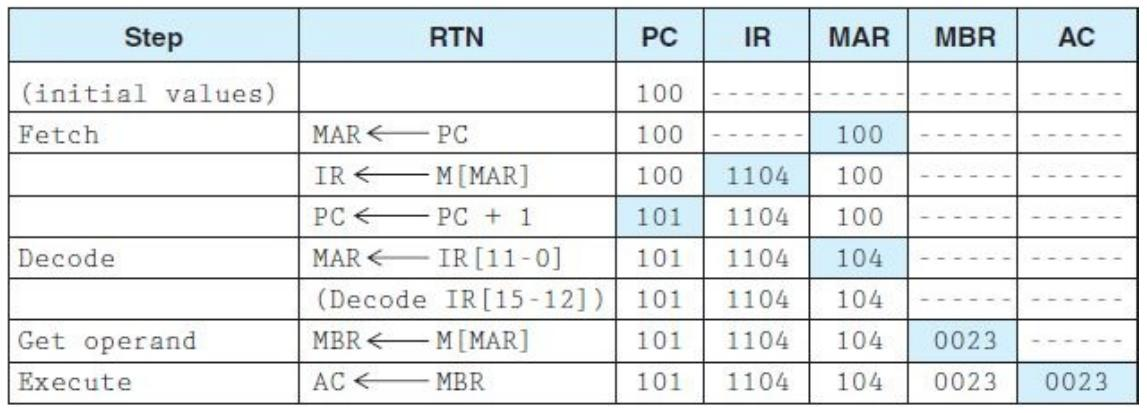 ADD 105 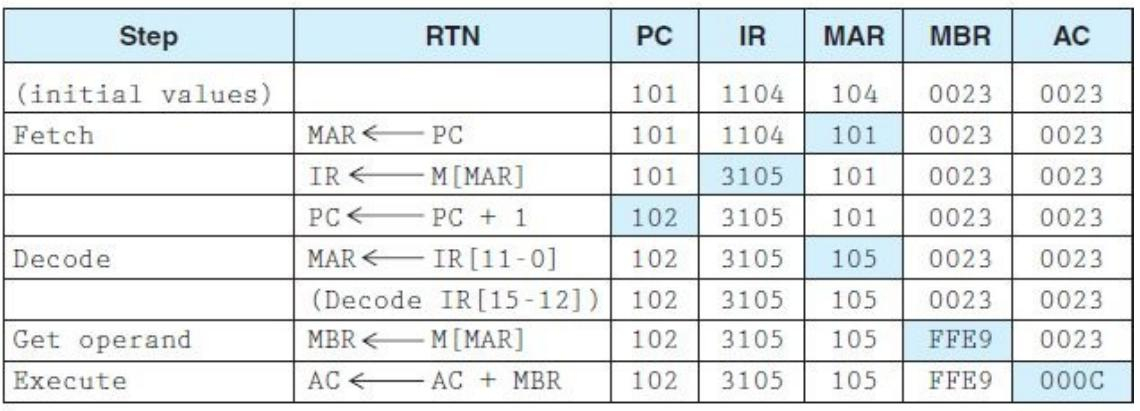 STORE 106 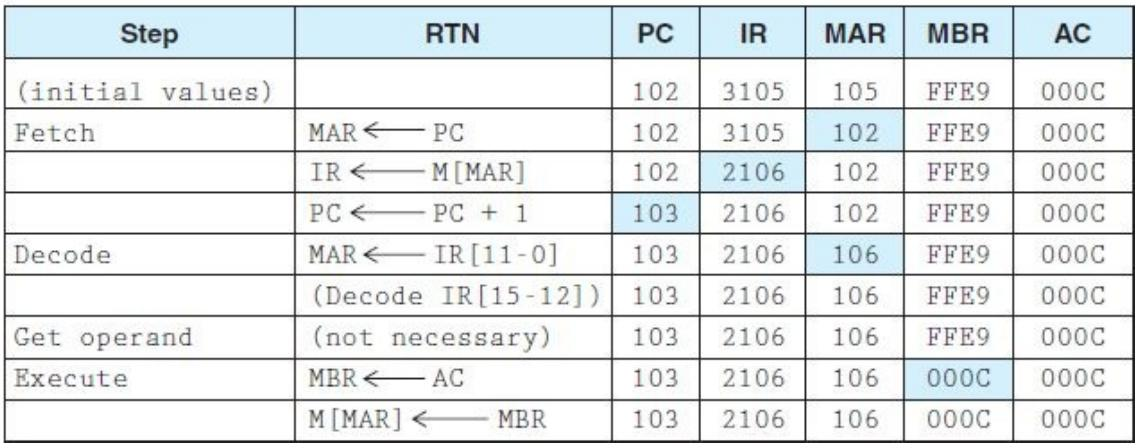 最后修改:2022 年 05 月 07 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
