Loading... # 存储器 ## 存储器类型 1. RAM(random access memory):随机存取存储器;包括dynamic RAM(DRAM,动态随机存储器,不断释放电荷,需要每隔几毫秒充电一次)、static RAM(SRAM,静态随机存储器,类似D触发器电路组成,比DRAM速度快。也更昂贵) 2. ROM(read only memory):只读存储器 ## 存储器层次结构 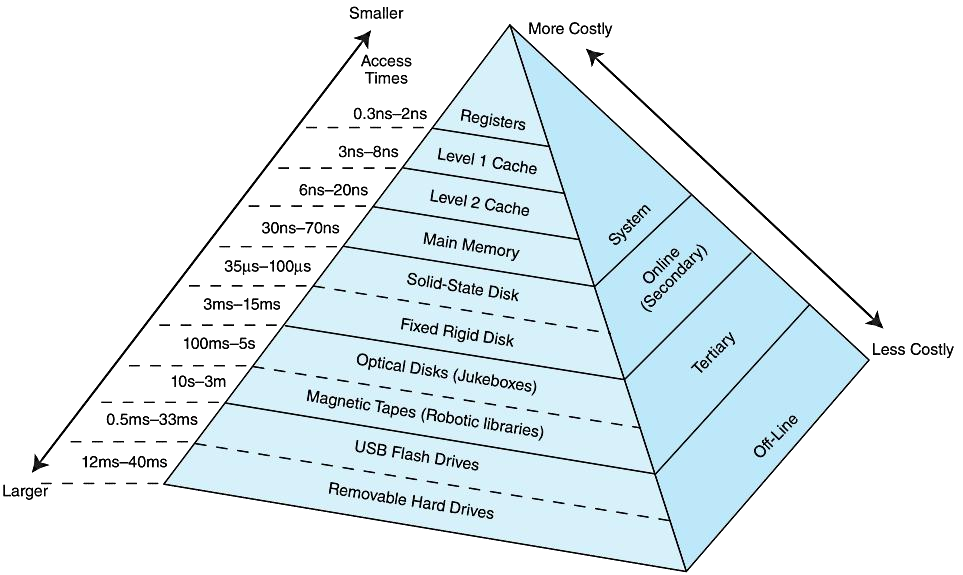 主要关注:**寄存器、高速缓存、主存和虚拟存储器(使用硬盘扩充地址空间)** 需要取一个数据,CPU按照:cache→main memory→disk的顺序查找数据,找到后将数据所在的整个数据块全部传给缓存,此时就出现一些定义 * 命中hit:访问的信息存在于给定层次的存储器中 * 失效miss:没找到 * 命中率:在给定层次存储器中找到所需信息的比率 * 失效率:找不到的比率,失效率=1-命中率 * 命中时间:找到的时间 * 失效惩罚:处理一次失效所需的时间,包括在较高层次存储器中替换一个块的时间和将所需数据传给处理器所需要的额外开销 存储器访问具有局部性(locality):即将来有可能访问现在位置附近的地址 * 时间局部性(temporal):最近访问的数据不远的将来会再次被访问 * 空间局部性(spatial):访问趋向于在地址空间中聚集(如数组、循环操作) * 顺序局部性(sequential):指令趋向于按顺序访问 **访问的局部性原则使得计算机系统可以使用少量的快速存储器来加速对主存的高效访问** ## 高速缓存 通过存储最近被用过的数据或将要访问的数据加快访问速度,缓存按照内容寻址(CAM,content addressable memory) ### 缓存映射策略 #### 直接映射 最简单的是`直接映射缓存`(direct mapped cache),**通过模的方式进行主存和缓存之间的块分配**,需要将主存块X映射到缓存块Y上(主存块多),模为N,此时Y=X mod N,如图 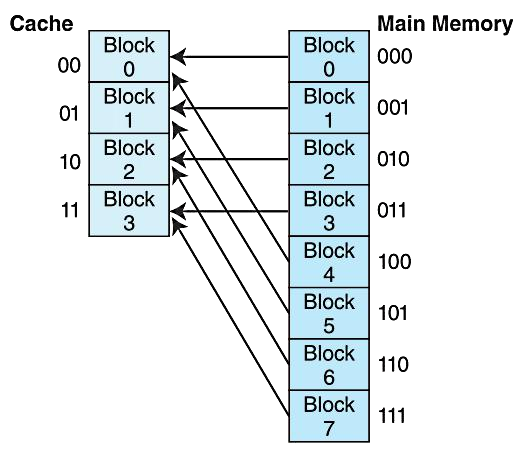 为了实现直接映射,将二进制主存地址划分为多个字段: 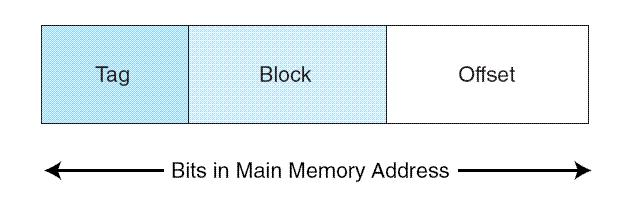 字段大小取决于**主存和缓存的物理属性** * 偏移字段(offset):每一个块中的字节数或字数决定偏移字段位数 * 块字段(block):缓存中的总块数决定块字段位数 * 标记字段(tag):剩余的位数 #### 全相联映射 直接映射缓存不需要查找,这种方式的缓存不像其他那样昂贵,每一个主存块在映射到缓存时都有一个特定的位置。 而`全相联映射`(full associative cache)不再给每个主存块指定唯一地地址,允许每个主存块存放在缓存的任意一块中,此时查找块映射的唯一途径就是搜索整个缓存,需要整个缓存都由相联存储器组成,要用专门的硬件实现查找,故价格昂贵 二进制主存地址这样划分  全相联映射允许主存的每一个块映射到缓存的任意一个块中,一旦主存块存放到了缓存中,为了找到某一指定字节中的内容,计算机需要**将主存地址的标记字段和缓存中所有的标记字段同时进行比较**,一旦找到对应的缓存块,就用偏移字段来定位该块内的所需数据 #### 组相联映射 `组相联映射`(set associative cache)是前两者的一种组合方式,采用N路组相联缓存映射:使用地址将主存块映射到特定的缓存块上,这点与直接映射相似;但不是让贮存地址映射到单一的缓存块上,而是映射到几个缓存块组成的一组上,这点与全相联映射相似。 对于2路(2-way)相联映射缓存 <u>逻辑视图</u> 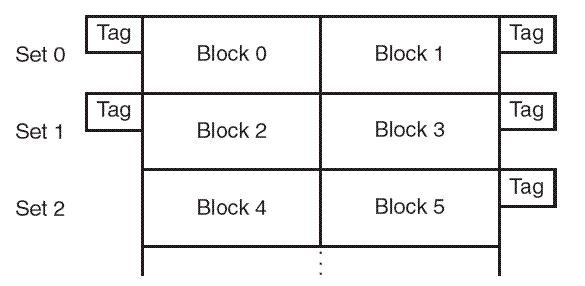 <u>线性视图</u> 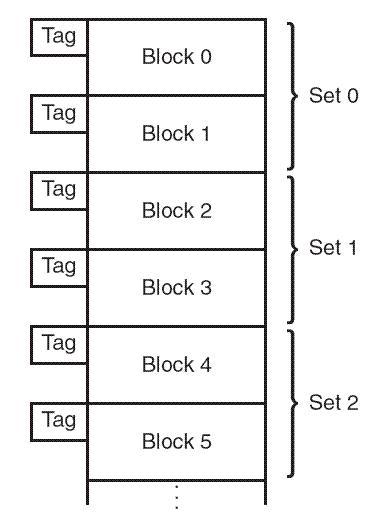 二进制主存地址这样划分  ***例题:*** Suppose a byte-addressable computer with a cache that holds 8 blocks of 4 bytes each. Assuming that each memory address has 8 bits and cache is originally empty, for each of the cache mapping techniques, direct mapped, fully associative, and 2-way set associative, trace how cache is used when a program accesses the following series of addresses in order: 0x01, 0x04, 0x09, 0x05, 0x14, 0x21, and 0x01. 1. 直接映射:3、3、2 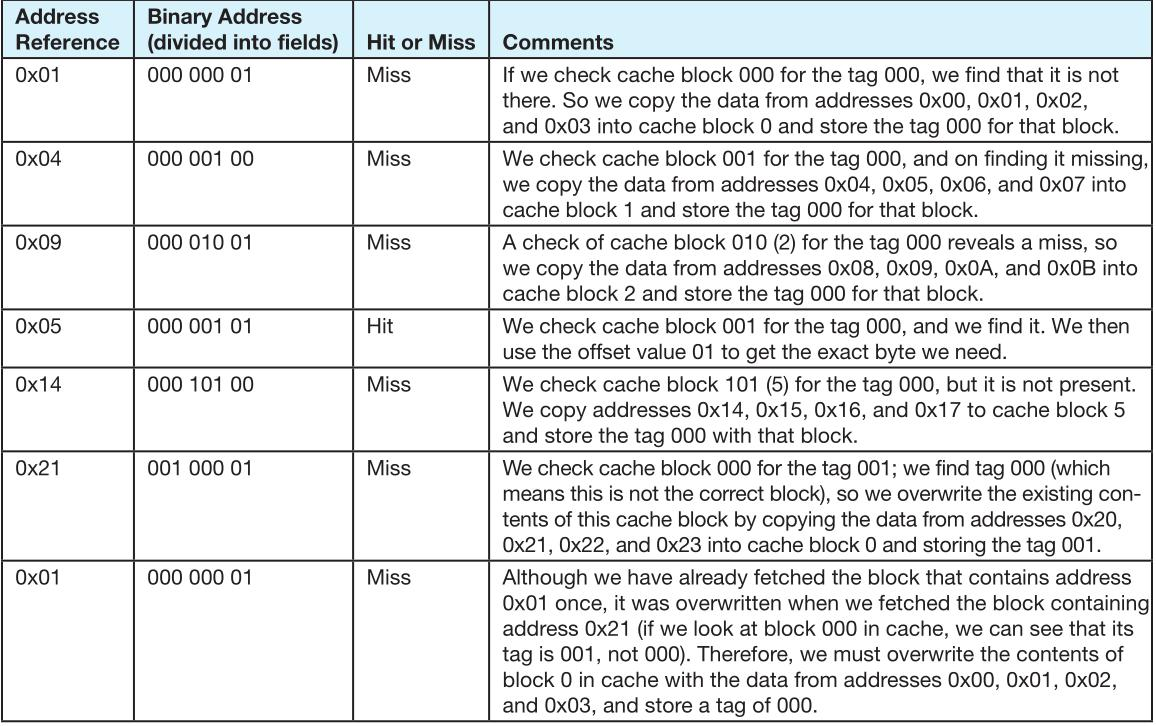  2. 全相联映射:6、2  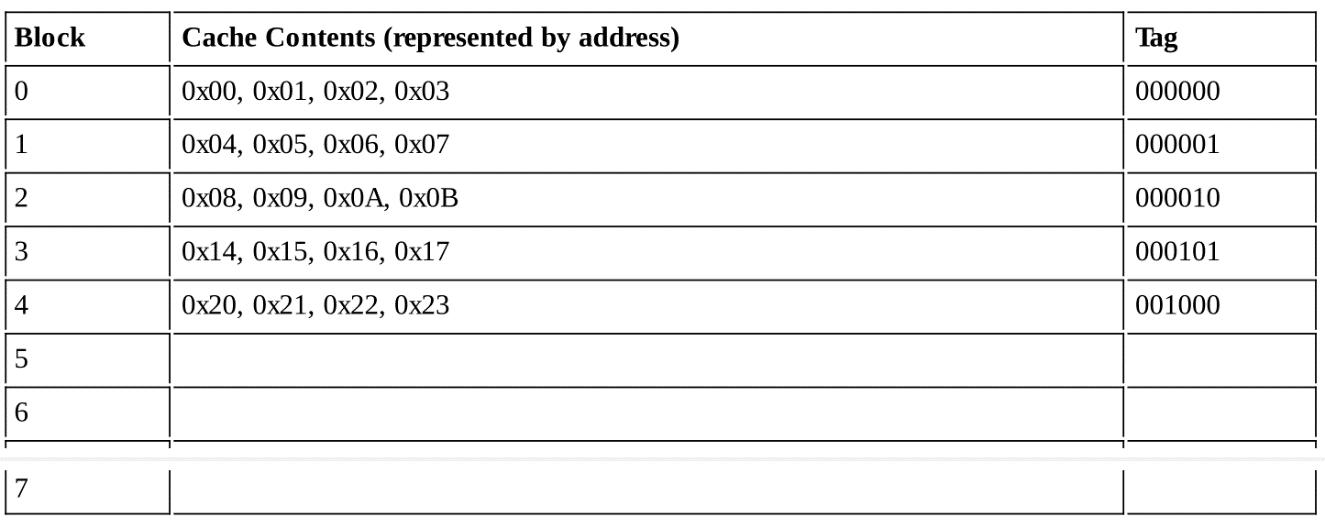 3. 2路组相联映射:4、2、2 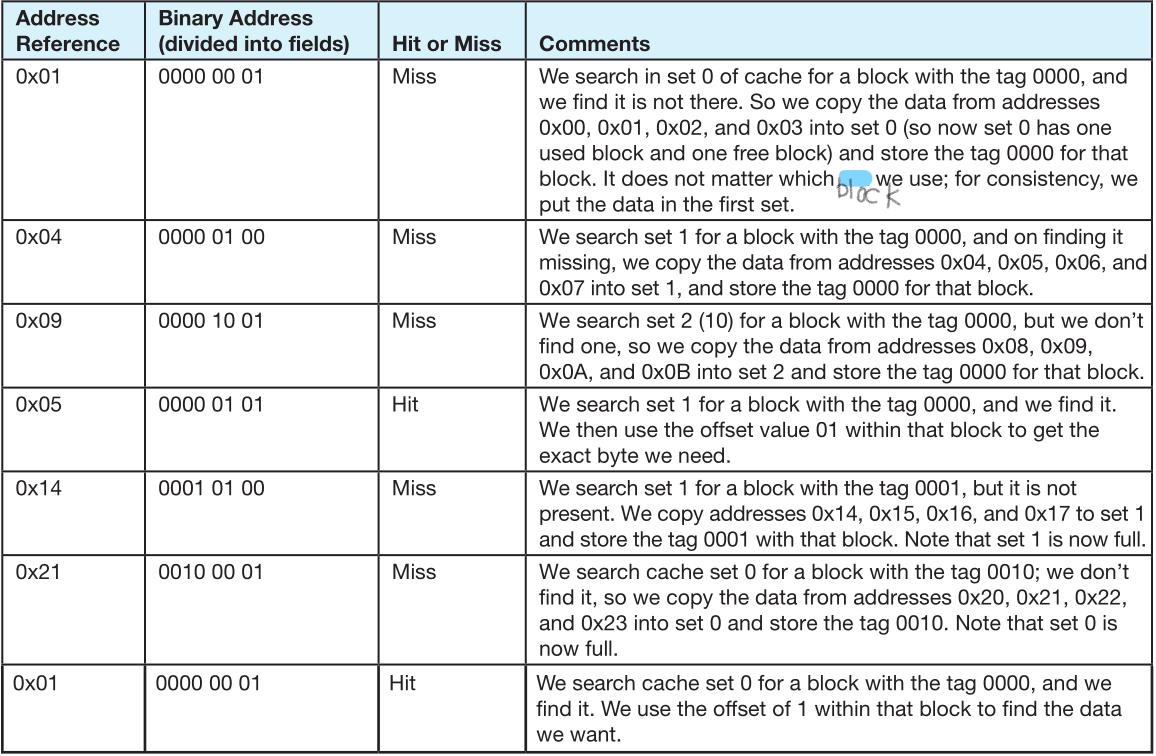 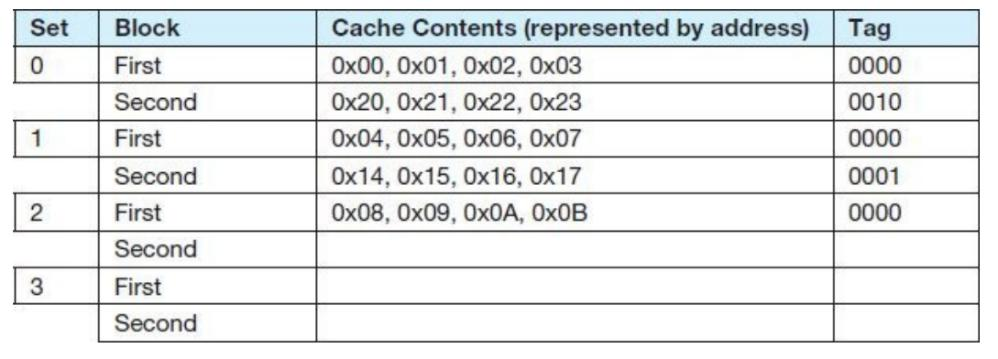 研究发现组相联映射性能优良,且2-16路缓存性能接近于全相联映射,成本缺只有其的一小部分。一次大多数现代计算机系统采用组相联映方案,最常见的是4路 ### 替换策略 在直接映射方案中,如果某一个缓存块有竞争现象,则当前块淘汰出缓存给新块,这个过程称为**替换**(replacement),因为新块的位置预先设定好无需替换策略。但是在全相联映射和组相联映射中,需要有替换算法来决定从缓存中移除的淘汰块 法一:**最近最少使用**(LRU,least recently used)算法 跟踪每一块最后一次被访问的时间并选择淘汰最近最少使用的块,需要记录每个缓存块的访问历史,占用很大空间,降低了缓存的处理速度 法二:**先进先出**(FIFO,first in first out)算法 在缓存中存在时间最长的块会被淘汰 法三:**随机选择淘汰**算法 和法二一样容易导致颠簸的恶化访问情形(不断移出调用),无法真正随机替换 ### 有效访问时间和命中率 命中率:在缓存在访问到数据的比率 有效访问时间:EAT(effective acess time) *EAT =H* *×* *$Access_{C}$* *+ (1-H)* *×* $Access_{MM}$ **同时访问缓存和主存**:若在缓存中找到数据,终止对主存的访问呢;若没在缓存中找到数据,就继续访问主存→访问在时间上存在重叠,可以有助于减少时间开销 **按顺序执行访问**:先找缓存再找主存 ### 缓存写策略(cache write policies) 除了决定选择哪块作为淘汰块,还要处理脏块(dirty block,存在缓存中已被修改的块) 法一:**写直通**(write through)对每次写操作,同时更新缓存和主存(缺点是系统速度慢,但可忽略因为大部分是读操作) 法二:**写回**(write back)仅当某个缓存块被替换出去才更新其对应的主存块,通常速度比写直通快(缺点是可能在某一时刻主存和缓存对应值不同) ### 数据和指令缓存 * 统一或集成缓存:保存很多最近访问过的指令和数据的缓存 * 哈佛缓存:大多现代计算机采用,指令和数据存放在单独的缓存中 * 受害者缓存:用一个小容量相联存储器来存放那些发生冲突时从CPU缓存中淘汰出来的块 * 跟踪缓存:指令缓存的一个变种,用于存储译码后的指令序列,指令再次需要时不需要译码了 ### 缓存的级别 ***多级缓存层次结构*** L1:8KB-64KB,位于处理器,访问时间大约4ns L2:64KB-2MB,位于处理器外部,访问时间15-20ns L3:2MB-256MB,在处理器和内存之间 * 包容缓存(inclusive):允许数据同时出现在多级的缓存 * 独占缓存(exclusive):保证数据最多在某一级缓存中 ## 虚拟存储器 虚拟存储器将硬盘作为RAM的扩展,增加了程序所能访问的地址空间 ### 分页 实现虚拟存储最常见的方法是分页,即将主存划分为固定大小的块,并将程序也划分为同样大小的块,程序块需要的时候调入主存 相关术语: * 虚拟地址:进程所使用的逻辑或程序地址 * 物理地址:物理主存中的实际地址 * 映射:虚拟地址映射(转换)到物理地址 * 页面:主存(物理存储器)分成大小相等的块 * 页(page):虚拟存储器(逻辑地址空间)分成的大小相等的块,大小等于页面 * 分页(page frame):将虚页从磁盘调入到主存中的过程 * 碎片:主存中不能使用的部分 * **缺页**:请求页没在主存,需要从磁盘拷贝到主存时发生的事 进程地址空间不需要连续存储到主存,用不到的部分会存放在磁盘的页面文件中 主存和磁盘使用**页表**来记录每一页的信息,每个进程都有自己的页表,通常存储在主存中 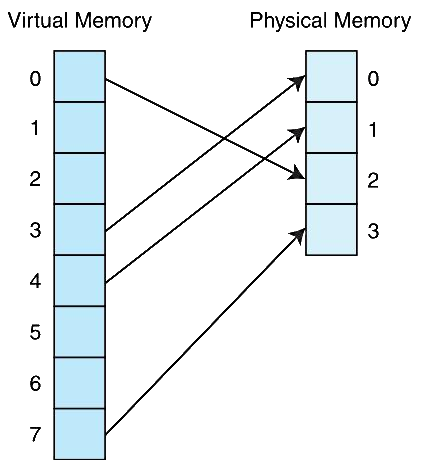 如果页在主存中,有效位置1,虚页号被实际页面号替代;否则置0,此时属于缺页故障,意味着需要从磁盘中找对应的页拷贝到主存的空闲空间 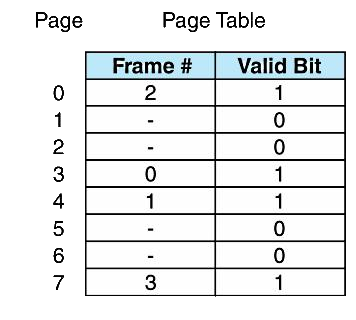 其他附加字段有:脏位(修改位)表示虚页是否被改变;附加位(使用位)表示页的使用情况 操作系统将虚拟地址翻译为物理主存地址,虚拟地址分为两个字段,**页域和偏移域**  页域决定地址所在页,偏移域决定地址在页内的位置 eg:虚存地址空间8K bytes,物理地址空间4K bytes,页的大小1K bytes,系统采用字节寻址 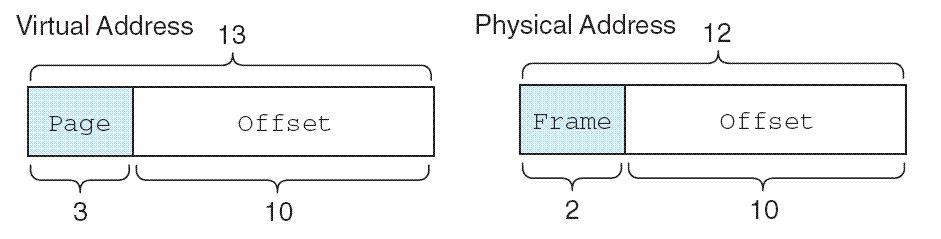 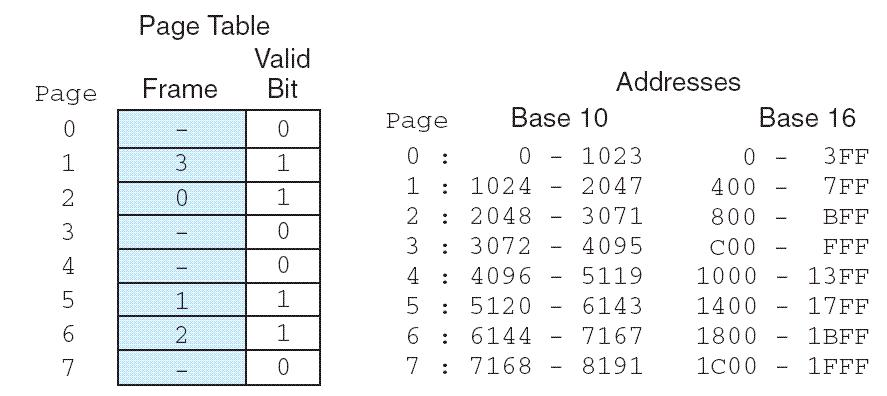 现有虚拟地址1010101010011$_{2}$=0x1553,转换为物理地址,取前三位得到页号,查看页表找对应的页面号,是01,进行替换得到物理地址010101010011$_{2}$=0x0553 使用分页管理的有效访问时间 EAT=(1-page fault rate)×t$_{主存访问}$×2+page fault rate×t$_{磁盘访问}$ **主存访问需要两次**:一次访问页表,一次访问主存中数据 通过页表缓存中存储**最近访问过**的叫做转换旁视缓冲器(TLB,translation look-aside buffer)来加速页表查找过程 每一条TLB记录包含一个虚拟页号和对应的主存页面号 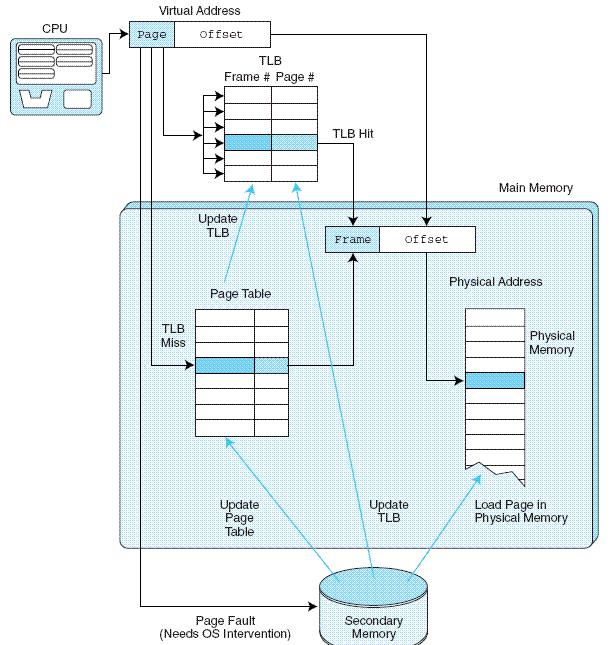 **查找地址步骤** 1. 从虚拟地址中提取页号 2. 从虚拟地址中提取页内偏移 3. TLB中并行产找虚拟页号 4. 找到:物理页面号+偏移字段 访问主存地址 5. 未找到:转去访问主存中的页表得到对应的页面号 将TLB、页表、主存汇合到一起: 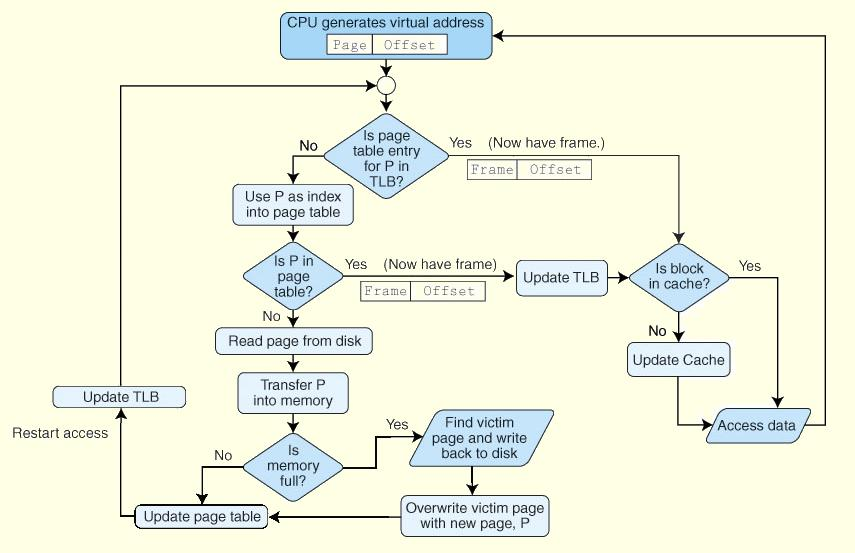 ### 分段 虚拟地址空间被分成逻辑可变长度的单元或段,物理存储器实际上不进行任何形式的划分。当一个段需要占用物理内存时,操作系统会**在主存中寻找足够大的空闲块来存储整个段**。每一个段都有一个**基地址**来表示它存储到了主存的哪个位置和**范围限制**,从而表明段的大小 由多个段组成的程序都有一个相连的段表来代替页表 分页→内部碎片 分段→外部碎片 eg: <img src="http://xherlock.top/usr/uploads/2022/04/1644685148.png" alt="image-20220423203250818" style="zoom: 50%;" style=""> **分页**,尽管有足够的空间可以给P4进程,但是装不下,它得等其他进程出来,属于**内部碎片** <img src="http://xherlock.top/usr/uploads/2022/04/363890107.png" alt="image-20220423203257926" style="zoom:50%;" style=""> **分段**, <img src="http://xherlock.top/usr/uploads/2022/04/1744839665.png" alt="image-20220423203459394" style="zoom:50%;" style=""> <img src="http://xherlock.top/usr/uploads/2022/04/3159950085.png" alt="image-20220423203520559" style="zoom:50%;" style=""> P2进程的S2段无法装下,等待 <img src="http://xherlock.top/usr/uploads/2022/04/281047355.png" alt="image-20220423203616704" style="zoom: 33%;" style=""> 尽管一个进程段出来,总空闲空间也够,因为不连续,P2的S2段依然无法放下 最终会变得到处都是碎片,即**外部碎片** <img src="http://xherlock.top/usr/uploads/2022/04/1039646298.png" alt="image-20220423203820995" style="zoom:33%;" style=""> 分页: * 优点:易于管理,因为所有块大小相等,空间的分配、释放、交换和重定位很容易;消除了外部碎片 * 缺点:页的大小通常比段小,会导致更多的开销(跟踪和传输页所需要的资源) 分段: * 优点:消除了内部碎片;支持共享和保护 组合使用:虚拟地址空间被分成可变长度的段,段再被分成固定大小的页,主存被分为大小相同的页面 最后修改:2022 年 04 月 23 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
