Loading... # pytorch.nn 1 ## nn.Embedding ~~~python torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None) ~~~ 随机初始化词向量,词向量值在正态分布N(0,1)中随机取值,生成一个查找表 主要参数: * `num_embeddings`:词典的大小尺寸,指的是单词数目 * `embedding_dim`:嵌入向量的维度,自定义,即用多少维度来表示一个单词 * `padding_idx`:默认填0,如果给定就填入,表示空缺的词语都补充某个单词 ~~~python embed = nn.Embedding(num_embeddings, embedding_dim) output = embed(input) ~~~ input的维度:[seq_len,batch_size] 输出:[seq_len,batch_size,embedding_dim] --- eg:假设有3个句子,每个句子4个词,共有10个不同的词,词和id对应后如下 第一个句子:[1,2,3,4],第二个句子:[1,5,6,7],第三个句子:[2,8,9,10] 经过转换1、1、2为三个句子第一个词,2、5、8为三个句子第二个词,以此类推,生成input即为`x = torch.LongTensor([[1, 1, 2], [2, 5, 8], [3, 6, 9], [4, 7, 10]])` ## nn.utils.rnn 这个文件下主要是和RNN的序列处理相关的函数 ### nn.utils.rnn.pack_padded_sequence *参考*: 【1】:总结的非常好,有图和代码https://www.cnblogs.com/sbj123456789/p/9834018.html 这个函数跟在embedding的处理后,主要处理其中空白的部分 eg:一个batch有5句话,有些句子里的单词数很少 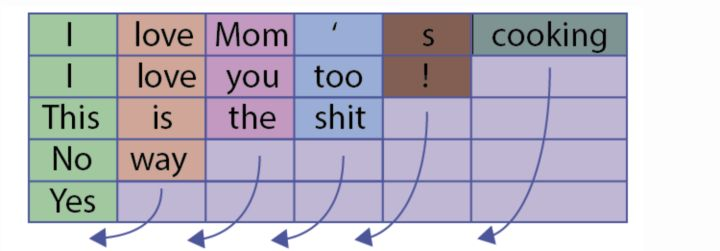 如果不用pack_padded_sequence会直接代入LSTM模型很多空白区 pack_padded_sequence的作用就是按列压缩,例如将上面的例子压缩为data和batch_sizes[5,4,3,3,2,1]  ~~~python nn.utils.rnn.pack_padded_sequence(input, lengths, batch_first=False) ~~~ 主要参数: * `input`:输入的数据,可以是[seq_len,batch_size,\*]的形式,seq_len为序列最大长度,且从长到短排列好(一般用sorted在Dataloader时就作处理);batch_first默认为False时按上面这个形状,batch_first=True时,格式必须为[batch_size,seq_len,\*] * `lengths`:输入数据的每个序列长度,是一个列表 * `batch_first`:根据输入形状自定义True or False 返回:一个PackedSequence对象 ### nn.utils.rnn.pad_packed_sequence() 功能和上面的相反,是将压缩后的序列再填充回来,一般是在经过模型处理完后填充回来 ~~~python nn.utils.rnn.pad_packed_sequence(sequence, batch_first=False) ~~~ 主要参数: * `sequence`:将要被填充的PackedSequence对象 * `batch_first`:同上 返回:填充过的序列、长度序列 ## nn.LSTM pytorch中LSTM的类实现 主要参数: * input_size:词嵌入的大小 * hidden_size:隐藏层的维度 * num_layers:隐藏层的层数,默认为1 * batch_first:True则输入输出的数据格式为 [batch_size,seq_len,feature] * dropout:除最后一层,每一层的输出都进行dropout,默认为: 0 * bidirectional:True则为双向lstm默认为False 输入: * input:(seq_len, batch, input_size) * $(h_0,c_0)$:隐藏特征和状态(初始记忆元) 传入是之前pack_padded_sequence处理后的PackedSequence对象也没关系,LSTM中forward对实例类型进行了判断来处理 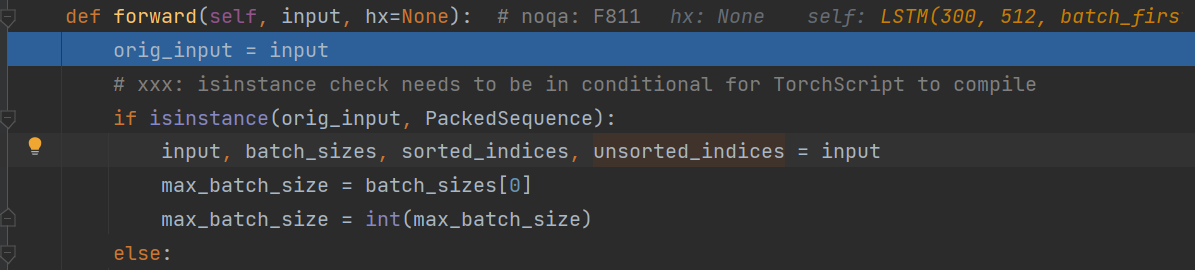 输出: * output(seq_len, batch, hidden_size * num_directions) * $(h_n,c_n)$:最后得到的隐藏特征和状态 一般我们取output和$h_n$,可以用下划线替代$c_n$ ~~~python lstm_out, (h, _) = self.lstm(embed) ~~~ 最后修改:2022 年 10 月 14 日 © 允许规范转载 打赏 赞赏作者 支付宝微信 赞 如果觉得我的文章对你有用,请随意赞赏
